

前回の記事では各種WebUIを一括導入、管理できる「StabilityMatrix」の導入部分を解説しました。

WebUIとして「Stable Diffusion WebUI Forge – Neo」をインストールしましたので、ここから実際に画像生成を行ってみたいと思います。
まずは画像が生成できるかどうかを試し、そこから基礎的な設定の詰め方を書いていきます。
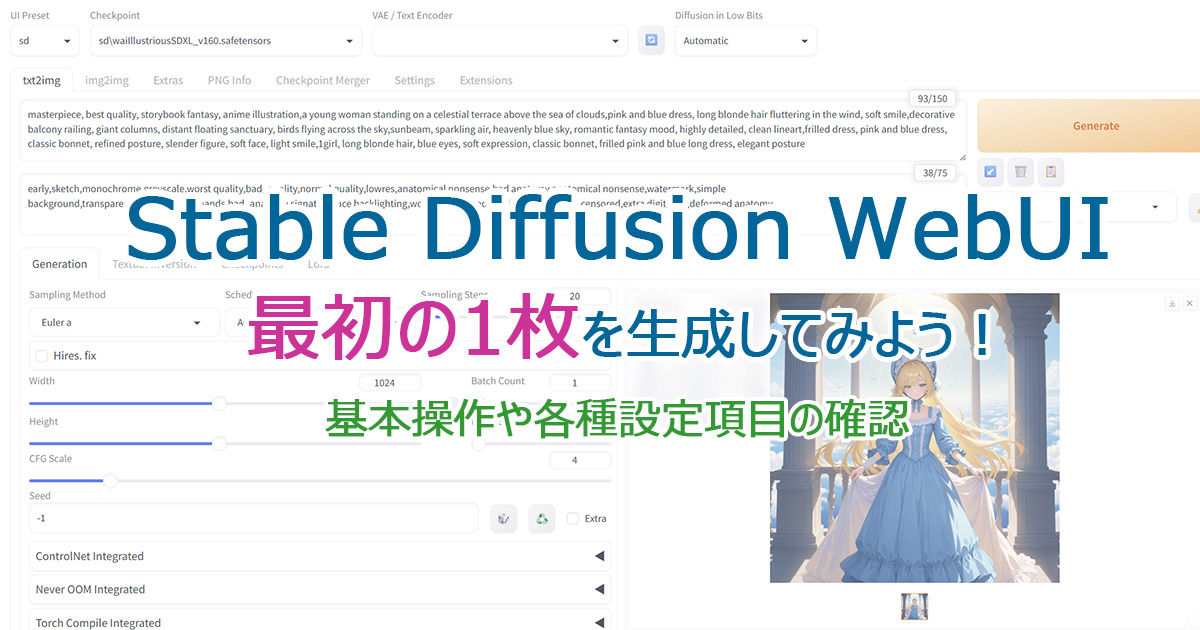
最初の1枚を生成してみよう
StabilityMatrixを起動、パッケージから「Stable Diffusion WebUI Forge – Neo」を起動します。
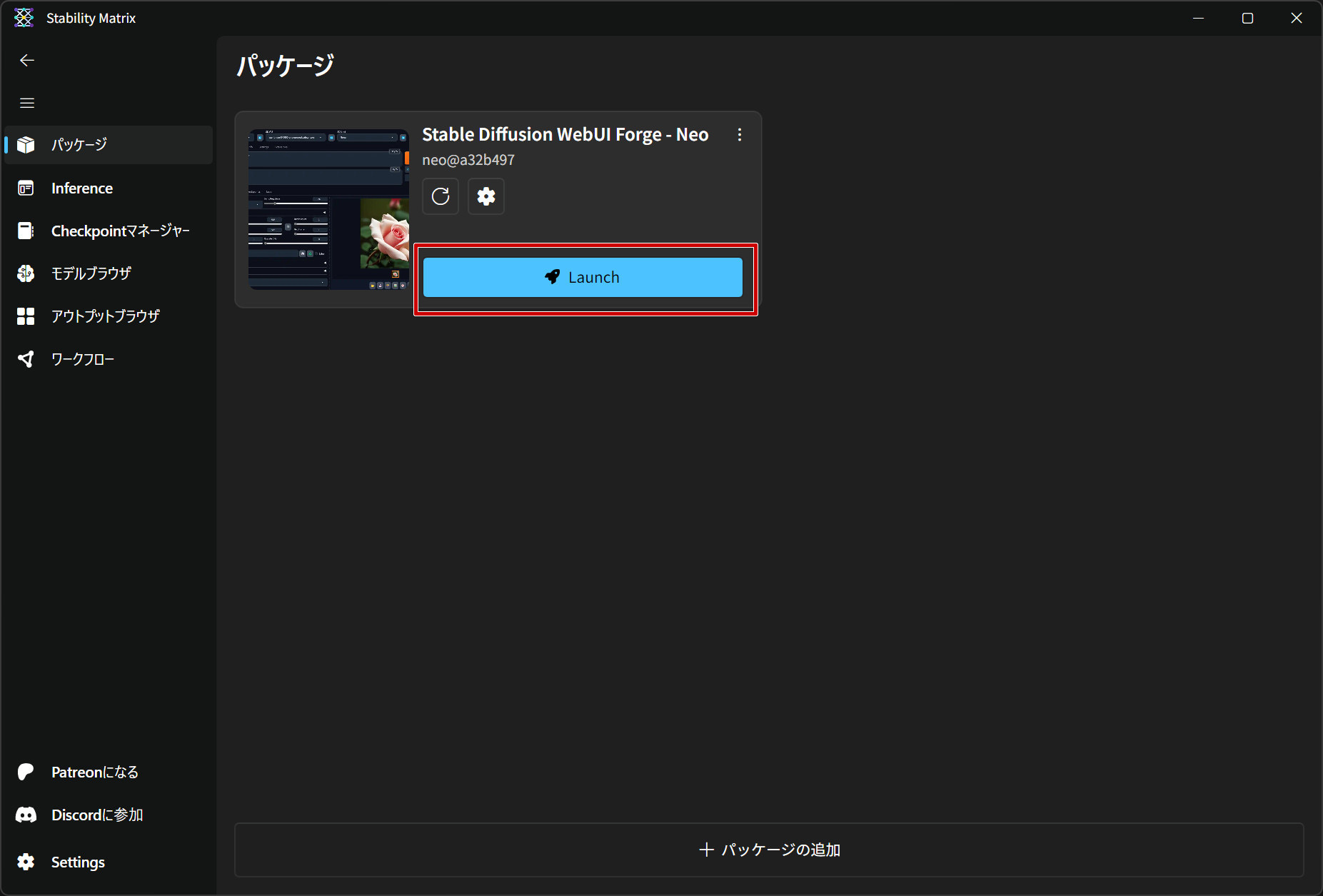
チェックポイントの読み込み
画面内に色々と設定する箇所がありますが、いったん後回しにして「まずは最初の1枚」を生成してみましょう。
最低限必要な設定は「モデル(チェックポイント)の指定、読み込み」と「プロンプト」の2つです。
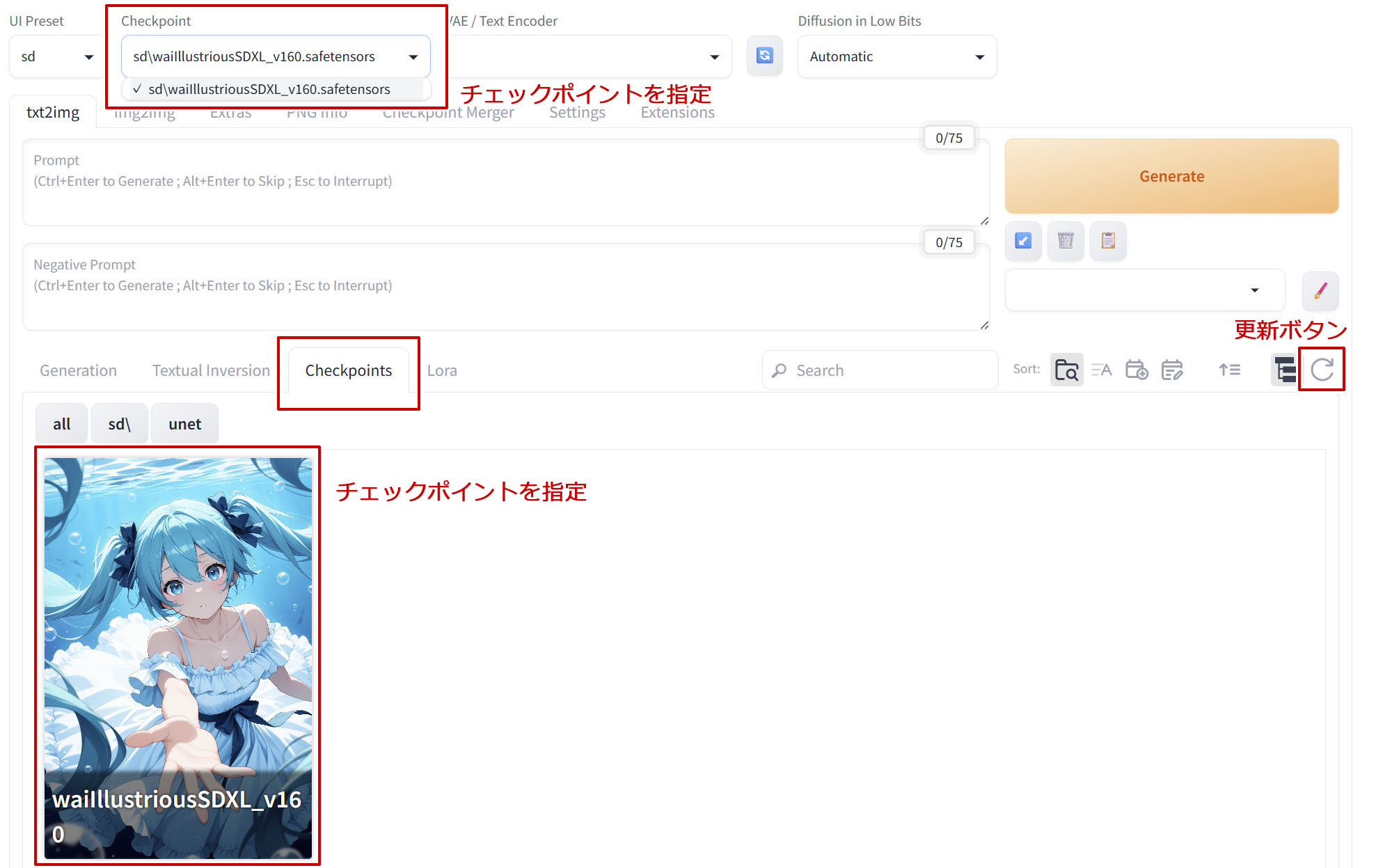
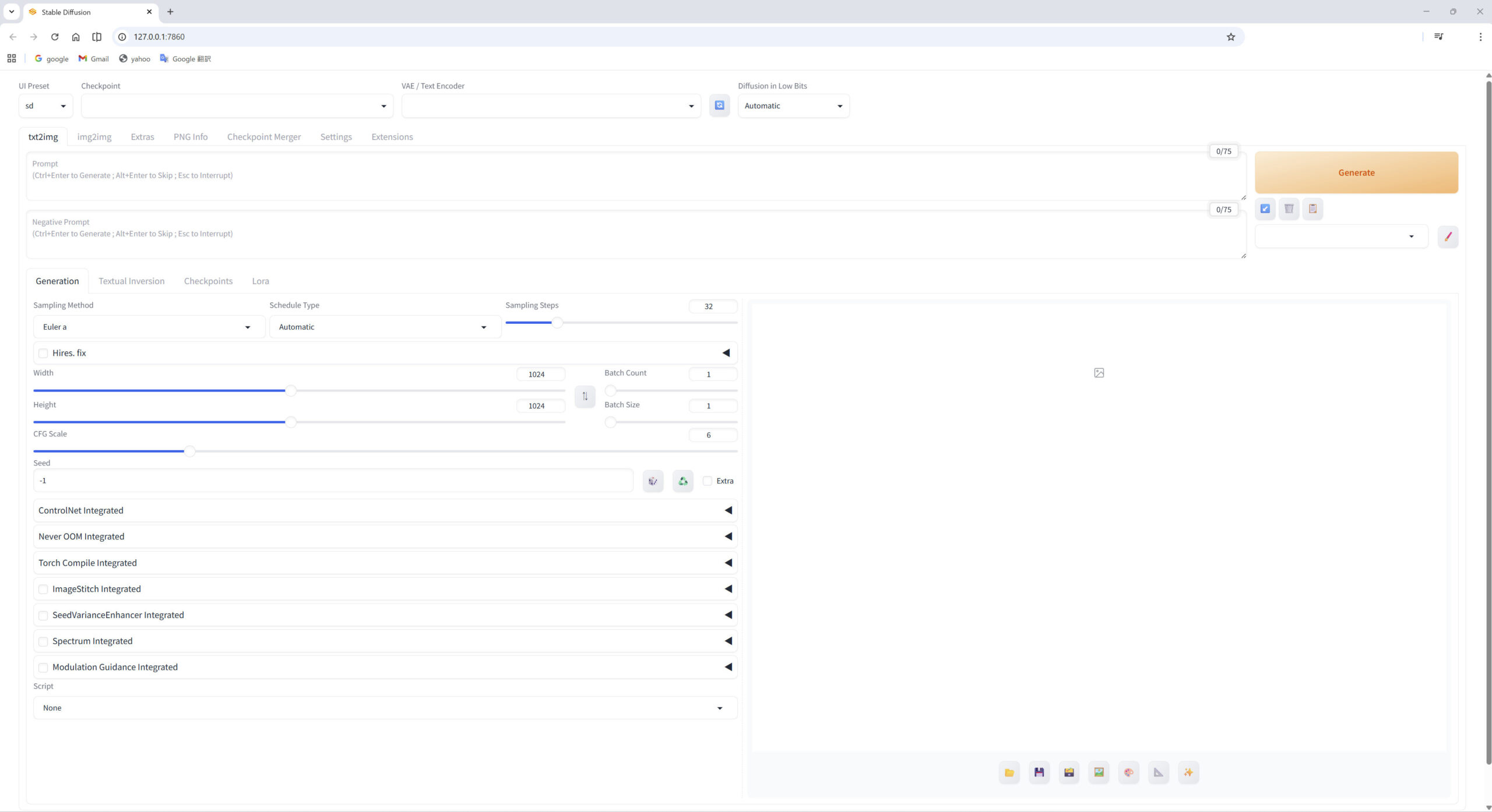
モデルデータである「チェックポイント」を読み込ませるために、画面上の「Checkpoint」、または真ん中にあるメニューの「Checkpoints」を開いて表示されるサムネイルを選択してください。
左上の「Checkpoint」に選択したチェックポイント名が入っていればOKです。
使用したいチェックポイントが見当たらない場合は、一番右にある更新ボタンを選択して再読み込みしてみてください。(一番上のDiffusion in Low Bitsの左にあるアイコンでも更新は可能。)
プロンプトの入力
次は、生成AIの肝となる「プロンプト(Prompt)」の入力です。
生成AIは、このプロンプトの内容を解析、解釈することで画像や動画などを生成します。つまり、ここに生成したい画像や動画の詳細を書き込むことで、自身が想像している映像をAIに出力させることができます。
左上のメニュー「txt2img」のすぐ下にプロンプトを入力する枠が上下に分かれて2つあります。上が「ポジティブ プロンプト」を入力する画面、下が「ネガティブ プロンプト」を入力する画面です。
また詳細は後述しますが、ここで簡単に説明いたします。
- ポジティブ プロンプト(Positive Prompt)
-
画面では単にPromptとのみ書かれていますがポジティブ プロンプトのことです。いわゆる「生成時に反映してほしい指示」のことで、例えば黒髪のキャラクターを描いてほしい場合、「black hair」と入れることで黒い髪のキャラクターを描いてくれます。
「反映してほしい」ので「ポジティブ(肯定的)」な指示です。
- ネガティブ プロンプト(Negative Prompt)
-
こちらは逆に「生成時に反映して”ほしくない”ものを指示」する場合に使います。例えば、画像生成AIにありがちな「人間の手が3本もある」などの奇形を抑制するため、「incorrect hands,extra limbs(余剰な手,余剰な腕)」と入力することでこれら奇形を出力させないように調整できます。また、想像と違うアイテムや構造が出力された際に、それらを出力しないように調整することもできます。
「反映してほしくない」ので「ネガティブ(否定的)」な指示です。
プロンプトの一例を見て分かる通り、プロンプトは原則「英語」で指示します。
日本語でも多少反映はしてくれるのですが、解釈が曖昧になりがちでうまく反映されないことが多いです。インターネット上では多くの方が「こういった描写をしたいときにはこのプロンプト」といった感じで公開してくれていますが、そのほとんどが英語になっているのはこれが理由です。
また、指示も原則は「単語」または「短い文」で指示し、それぞれを「,(カンマ)」で区切ることで複数の指示を行ないます。(最近のベースモデルは長い文章や自然言語を解釈できるようになってきていますが、この場合でも今のところは英語で指示するのが無難です。)
といっても最初はよく分からないと思いますので、今回は一例として以下のプロンプトを入力してみます。
- ポジティブ プロンプト
-
masterpiece, best quality, amazing quality, 1girl, solo, smile, long hair, white shirt, looking at viewer, outdoor, daylight最初は画質の指定で「傑作、最高品質、驚くべき品質」といったような内容です。AIは品質の違いはある程度区別できるのですが、「善し悪し」は判断できないためこの定型文を使います。「高品質は良いことでしっかり反映する」とちゃんと指示する必要があります。この定型文は今後もお世話になります。
続く指示は「一人の女性、笑顔、ロングヘアー、白いシャツ、カメラ目線、野外、日差し」で、主役のキャラクター像、表情、服装、目線、背景を順番に指定しています。ここを如何に詳細に記述できるかが生成AIの肝になりますが、今回はシンプルに指定してみます。(残りの部分はAIが勝手に判断します。)
- ネガティブ プロンプト
-
bad quality, worst quality, worst detail, sketch,nsfw同じように品質の指定を行なっています。「画質が悪い、最悪の画質、ディテールが最悪、ラフ画、NSFW」といった内容で、「低品質は悪いことで反映してはだめ」と指示しています。最後のnsfwは成人向けの表現を抑制しています。
ポジティブ プロンプトと矛盾しないような指示が望ましいです。ポジティブで「smile(笑顔)」を指示したのに、ネガティブも「smile」を入れるとAIが混乱して指示通りにならない可能性があります。
画像の生成、出力
ついにここまで来ました。最後に画像を生成させてみましょう。
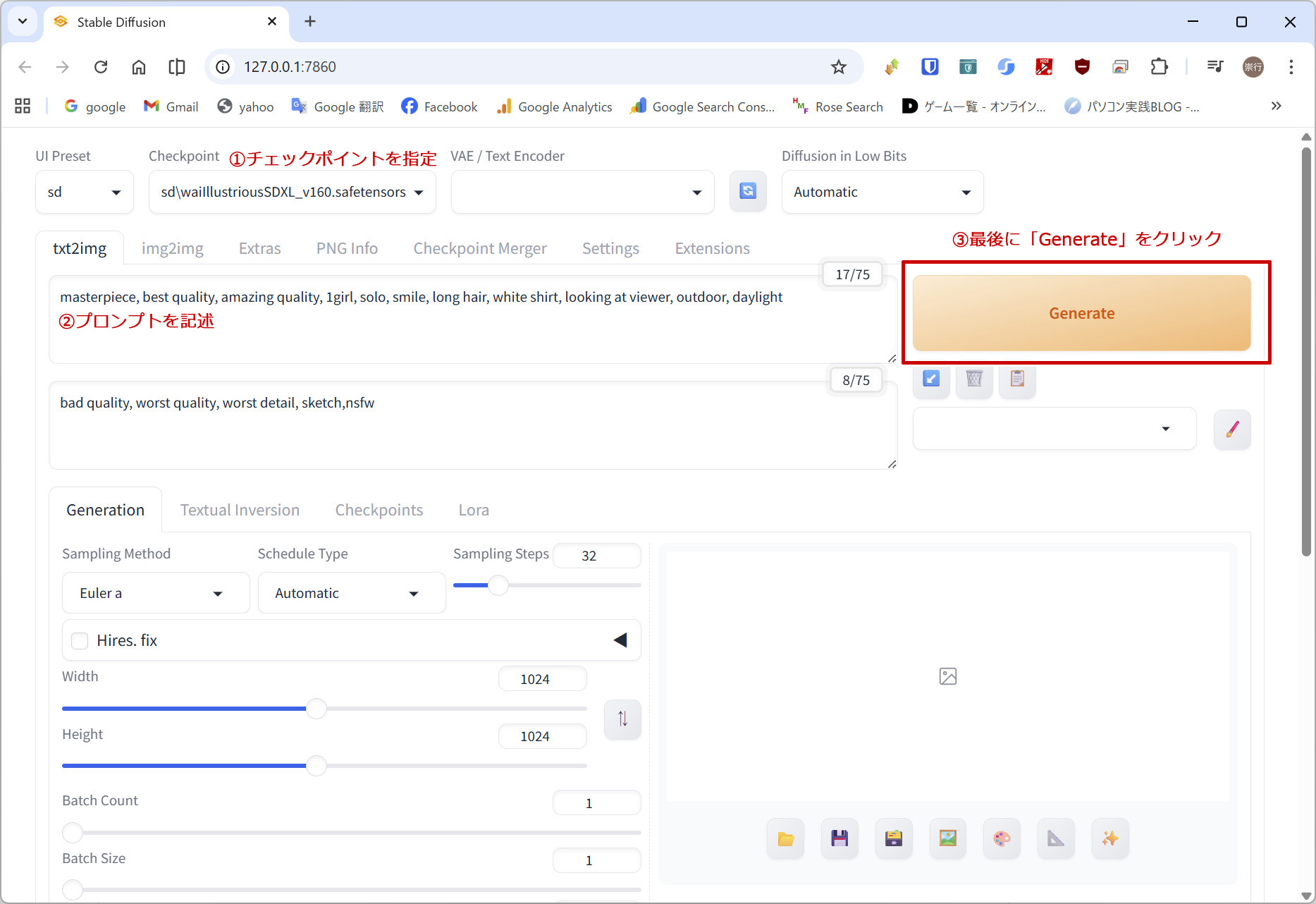
チェックポイントを指定し、プロンプトを入力したら、右上の「Generate」ボタンを選択します。生成中になるとボタンが「Interrupt」ボタンに表記が変わります。因みに、ショートカットキー「Ctrl+Enter」でも開始できます。
最初の1枚を生成するとき、まずはチェックポイントデータをロードする手順が入るので初回は少し時間がかかります。ロードが終わると生成が始まります。
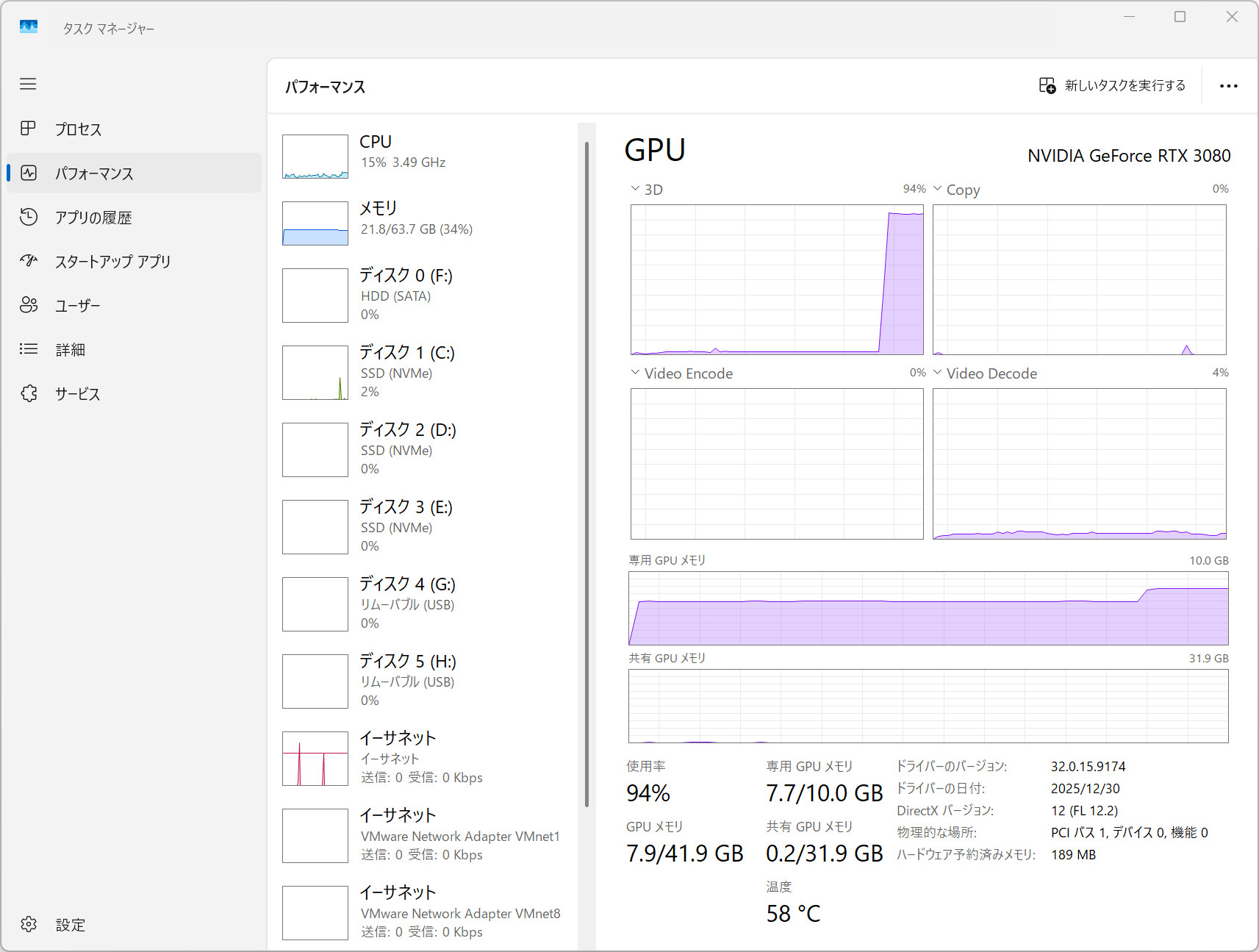
タスクマネージャーなどで確認するとストレージでチェックポイントのロードが始まること、ロードが終わるとGPUが頑張り始めるのが分かります。また、StabilityMatrixでは生成中の進捗状況が詳しく分かります。
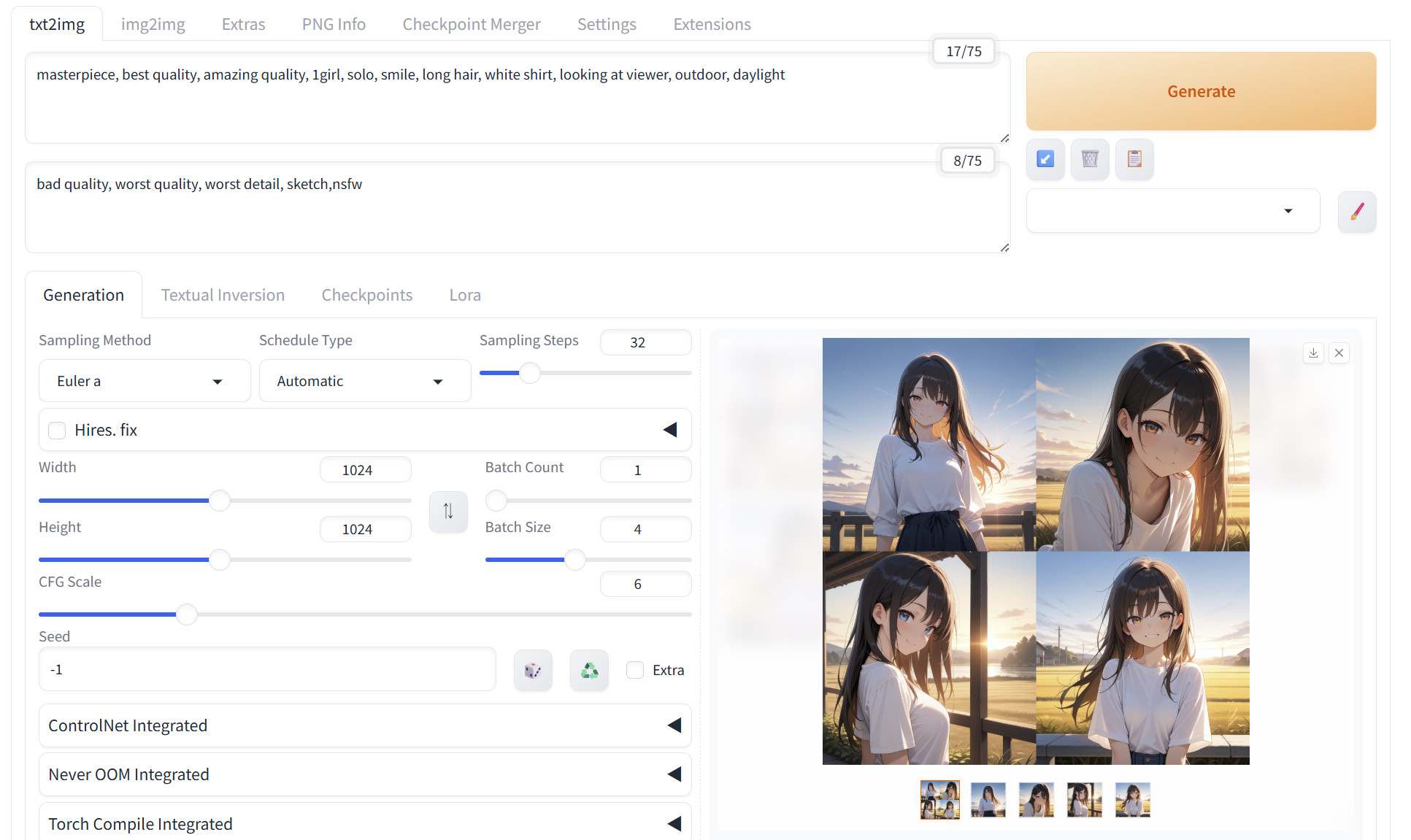
生成完了!画像の保存先を確認
進捗が100%になれば画像生成完了です!
StabilityMatrixのインストールからお付き合いいただきました場合は、長く解説してきましたが、これで最初の目的は達成いたしました。お疲れ様でした。
生成された画像をクリックすると拡大ができます。また、生成画像の下にフォルダーアイコンがありますが、ここをクリックすると生成した画像を保存しているフォルダーが開きます。
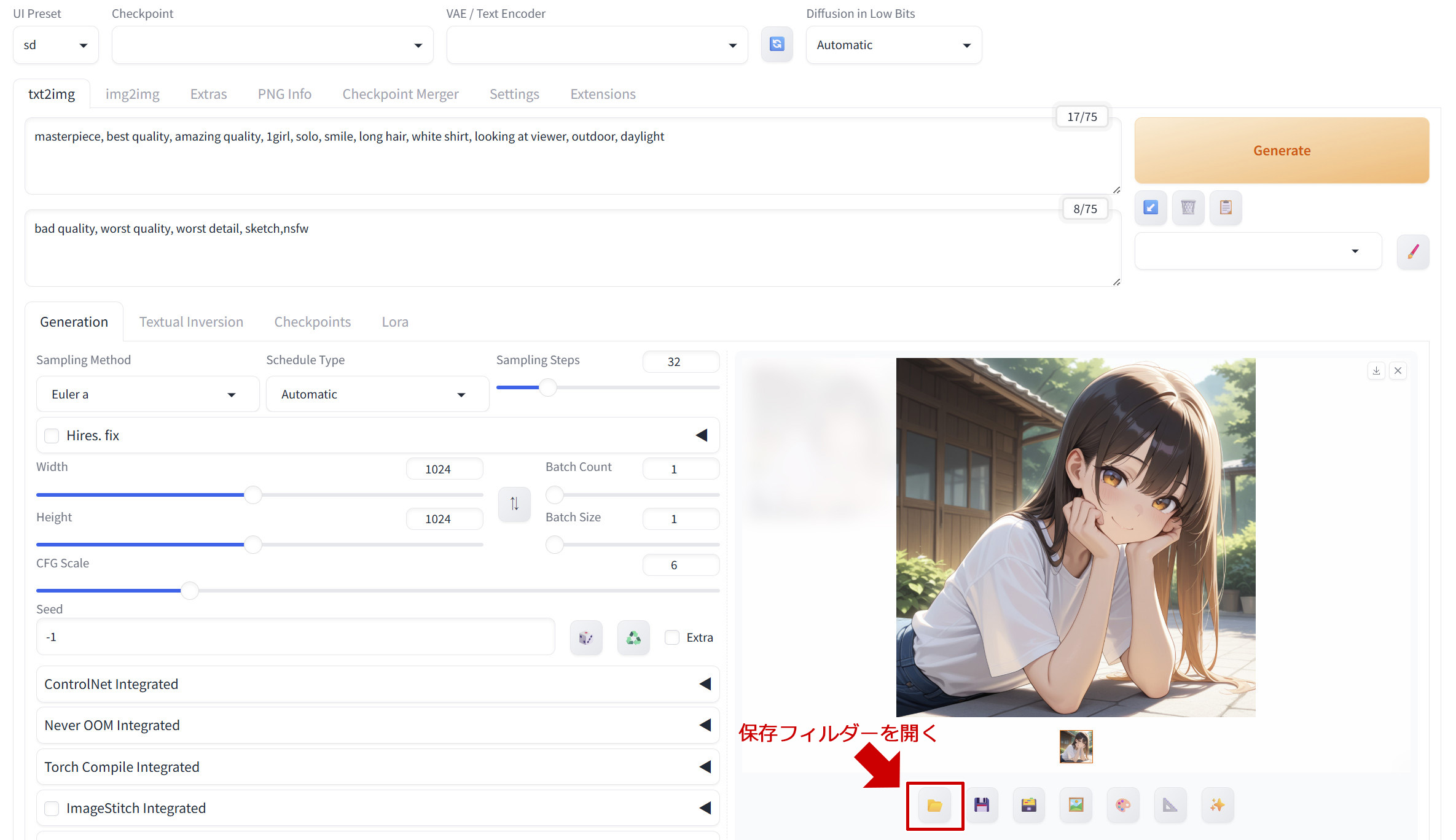
標準では以下のフォルダーに保存されるようになっています。
\Data\Packages\forge-neo\output\txt2img-images\ただ、StabilityMatrixを使っている場合、このフォルダーはシンボリックリンクが張ってあるようなので、実はデータの実体はここではなく以下のフォルダーに入っています。どちらからでも画像は確認できます。他のWebUIでも基本的にはこの「\Data\Images\」内のフォルダーを共有します。
\Data\Images\Text2Img\生成を途中で停止したい場合
画像生成途中でも何となくの構図がサムネイルとして表示されますので、「ちょっと思ったのと違うな」と感じたら生成途中でもキャンセルをすることができます。
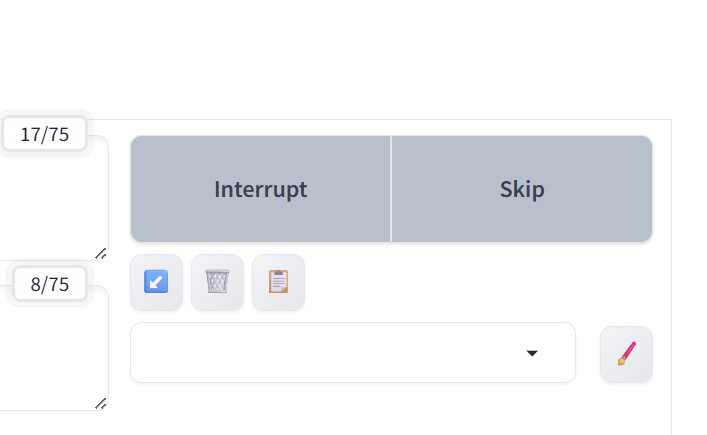
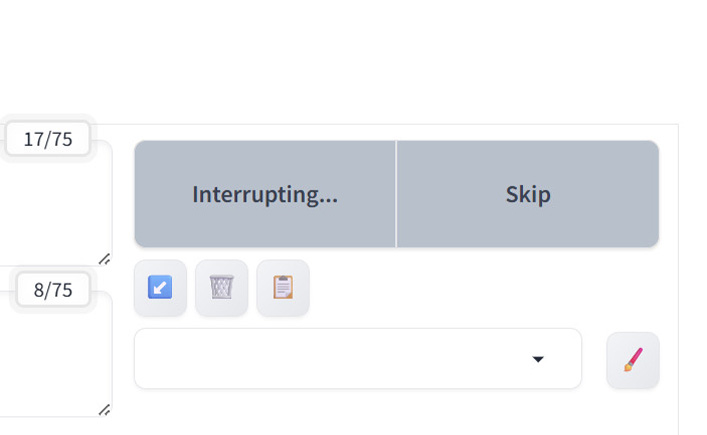
生成が始まると「Generate」ボタンが「Interrupt」へと変わります。生成途中で「Interrupt」をクリックすると「Interrupting…」となり、現在生成している画像の生成を止めます。複数枚の画像を生成している、つまりキューが複数ある場合でも全行程を停止させます。
「Skip」ボタンは、「Batch count」項目の数値が「2」以上の場合、つまり複数枚の画像を生成するよう指定しており(バッチ処理)、次のキューがある場合に、現在の生成を中断して次の画像を生成します。
同じプロンプトでも生成するたびに出力は変わる
プロンプトで入力した内容を変更しないまま再度生成せると、また違った画像が出力されることがわかります。
これは、プロンプトの指示内容や、指示にない部分の情景などを毎回AIが考えて生成しているためで、狙ったような画像がでてくることもあれば、ちょっと思っていたのと違う画像がでてくることもあります。
プロンプトを考え抜いた上であってもこれは変わらないので、最後は何枚も同じプロンプトで生成してみて「これだ!」と思う画像が生成されるのを待つということも必要になっていきます。最終的には試行回数が物を言います。
※後述しますが、「Seed(シード)」と呼ばれる値を固定させた状態だと、同じプロンプト、同じ設定であれば同じ画像が出力されるようにすることもできます。これを利用して、少しずつ画像に修正を加えていく方法もあります。
モデルの詳細ページに推奨プロンプトの記載がある場合
モデルの詳細ページに推奨プロンプトの記載がある場合がありますので、もし指定されている場合はなるべく合わせてプロンプトを指定するとよいでしょう。(特に品質に関するプロンプトの推奨が多いです。)
例えば、今回利用している「WAI-illustrious-SDXL」というモデルであれば、以下のようなプロンプトが推奨されています。
●Positive Prompt
,masterpiece,best quality,amazing quality,●Negative Prompt
bad quality,worst quality,worst detail,sketch,censor,プロンプトの違いによる絵の変化
プロンプトの指示によって出力される絵は大きく変化しますので、このプロンプトをどう入力していくかが生成AIを使いこなしていくに当たって特に重要なことになります。
試しに先のプロンプトを少し変えてどのように変化するか確認してみます。

masterpiece, best quality, amazing quality, 1girl, solo, shy, long hair, white shirt, looking at viewer, outdoor, daylight表情を「shy(シャイ、恥ずかしがる)に変更。

masterpiece, best quality, amazing quality, 1girl, solo, smile, white hair silver hair,long hair, schooluniform, cowboy shot,outdoor, night, moonlight髪色を「銀髪(white hair silver hair)、衣装を「学校の制服(schooluniform)」、カメラングルを「膝から上(cowboy shot)」、背景を「夜間、月夜(night, moonlight)」へ変更。

masterpiece, best quality, amazing quality, 1girl, solo, one eye closed, purple hair,long hair, Mage, Wizard robe, Wizard Hat, side angle, side view,outdoor, Medieval town, fantasy「紫髪(purple hair)」「片目を閉じる(one eye closed)」「魔法使いスタイル(Mage, Wizard robe, Wizard Hat)」「横からのアングル(side angle)」「中世風のファンタジー背景(Medieval town, fantasy)」へ変更。
しっかり指示したプロンプトに従って容姿や背景が変わっていくことがわかります。
指示していない箇所はAIが判断しているため、例えば「月夜(night, moonlight)」とのみ指定しても明かりの付いた家屋や電灯など、プロンプトの内容を考慮して自動で夜の町並みのような背景が追加されています。
カメラアングルの指示は、絵にストーリー性を持たせるのに特に重要な要素で、例えば全身が映ってほしい場合は「full body」「full shot」、上から撮影した感じにする場合は「from above」、逆に下からは「from below」など、カメラ位置の指定も柔軟に対応しています。
また、AIはプロンプトの最初に書かれている方の指示を優先し、後ろになるほど優先度が低くなります。このため、絶対のルールでもありませんが「主題 → 属性 → 構図 → 背景 → 光・色」のような指示の仕方にすると、キャラクター像から優先されるため思い描いたイラストになりやすいです。
今回で言えば
- 主題 → 1girl, solo で一人の女性
- 属性 → long hair, white shirt でキャラクターの属性
- 構図 → looking at viewer でカメラ目線
- 背景 → outdoor で野外
- 光・色 → daylight で日差し
といった指定にしています。逆に背景の方が大事ならそのプロンプトを最初に持っていってもよいです。
プロンプトはインターネット上の有志により、「こういった表情やポーズはこのプロンプト」のように反映されやすいプロンプト例を公開してくれていますので、翻訳機能(Google翻訳など)だけでは表現が難しく困ってしまったときはこれらのサイトを参照にするとよいでしょう。(本当に自由にイラストを動かせるようになってくるので、これらプロンプトを「呪文」と読んでいる方もいらっしゃいます。)
因みに、大規模言語モデルである「ChatGPT」や「Gemini」などに聞いてもいいです。生成AI向けのプロンプトを生成AIに任せるという、何とも言えない状況になりますが、意外にもしっかり提案してくれますのでおすすめです。
プロンプトの改行、コメントアウト
プロンプトは詳細にするほど長く煩雑になりがちですが、読みづらい場合は「コメントアウト」でメモを残すこともできます。改行も可能なので、分かりやすいように以下のようなプロンプトで入力しても大丈夫です。
※コメントアウト:特定の記号を使って一部のコードの実行を無効化するプログラミングテクニック。コメントアウトした箇所は実行されなくなるため、この部分にコードの詳細などをコメントとして残しておき、見やすく整理することができます。
#品質指定
masterpiece, best quality, amazing quality,
#主題
1girl, solo,
#属性
smile, long hair, white shirt,
#アングル
looking at viewer,
#背景
outdoor,
#光
daylight「#」以降の行は指示に含まれず無視されますので、これでコメントアウトとして機能します。画像のPNG infoにも残りません。
プロンプトの強調、重み付け
Stable Diffusion WebUIでは、プロンプトワードに重みを付けて指示の重要度を調整することができます。
() で強調する
最も基本的な構文で、丸括弧 () で囲むとそのワードを強調できるという書き方です。括弧内のワードが強調されてより画像に反映されやすくなります。(必ず反映されるわけでもありませんが、優先はされやすくなります。)
1girl, red dress, (smile)丸括弧は重ねることができ、重ねるほど強調が強くなります。
(smile) = 1.1倍の強調
((smile)) = 1.21倍の強調
(((smile))) = 1.331倍の強調括弧を重ねるごとに 1.1 倍ずつ掛け算されるイメージです。強調しすぎると、かえって不自然になったり、その要素ばかりが強く出て全体のバランスが崩れたりすることがありますので、出力画像を見ながら調整していきます。
(word:1.5) のように数値で重みを指定する
どちらかというとこちらが分かりやすく主流。(ワード:数値) の形で重みを直接指定できます。
(smile:1.3)
(red eyes:1.5)
(background:0.8)数値部分がそのまま倍率になります。「1」に指定すると何も変化しません。また、1未満の値にするとその要素を逆に弱めることもできます。ただ、その要素を無くしてほしい場合はネガティブプロンプトへ記載した方が効果が高いです。ネガティブプロンプトでも強調構文は使えます。
倍率は高くても2倍程度までにしておくことがおすすめ。それ以上だとバランスが崩れることが多くなります。
品質、解像度、プロンプト影響度などの調整
ここまでで、画像生成AIに必要な最低限必要な「チェックポイントの読み込み」「プロンプト」ができました。
次からは細部を詰めていく作業になります。
今度は画像生成AIにとって大切なパラメーターとなる「サンプリング方式」「ステップ数」「画像解像度」「プロンプトの影響度」などを指定してみたいと思います。これはStable Diffusionに限らず他のWebUIでも同じ項目がありますので、画像生成AI共通の設定項目になります。
画面真ん中辺りに「Generation」というタブがありますので、こちらを選択します。
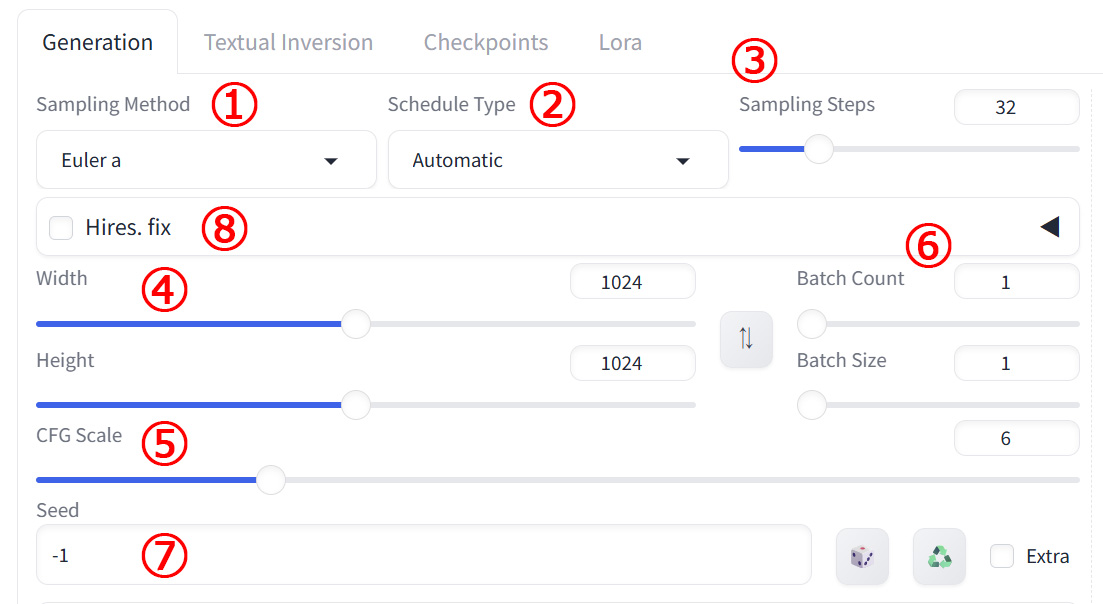
1. Sampling Method(サンプリング メソッド)
生成時に使用するサンプリング方法を指定します。単に「サンプラー」とも呼ばれます。
画像生成の基本的な動作ですが、最初にランダムなノイズだらけの状態から始まり、そこから段階的にノイズを減らして画像を整えていくという方法で生成しています。
https://stable-diffusion-art.com/samplers/ より引用 The sampler is responsible for carrying out the denoising steps.
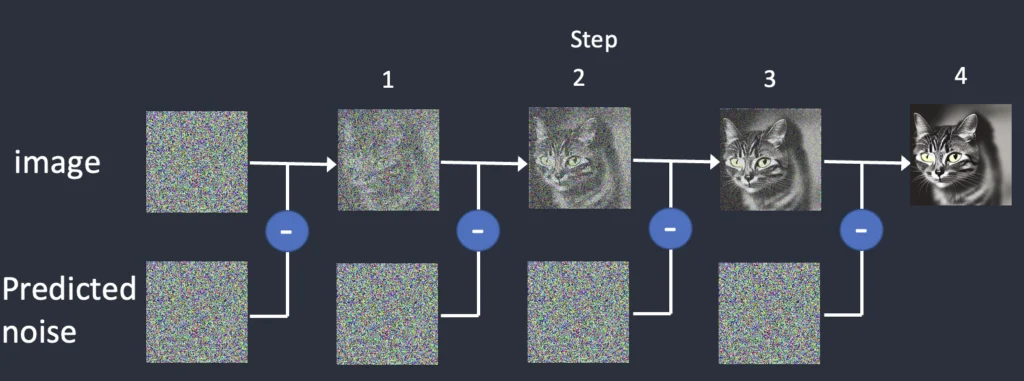
この「少しずつ整えていく計算のやり方(サンプリング)」を決めるのが「サンプラー」の役割です。
サンプラーによってノイズの計算方法(ノイズ予測や除去、加算など)が異なっているため、例え同じモデル、同じプロンプトであっても出力する画像や生成速度に変化がでます。
サンプリング方法が違うと、目的とする画像を生成するための計算ルートが変わるので、
- 線の出方
- 細部の安定感
- 破綻のしにくさ
- 生成速度
- 同じStep数でも出る絵の傾向
などが変わります。
つまり、プロンプトが同じでも、サンプラーが違うだけで印象が変わることがあります。
Stable Diffusion WebUIに標準で搭載されているサンプラーがいくつかありますが、定番のサンプラーがありますので、まずはこれらを利用するとよいでしょう。
特にモデルの詳細ページに推奨のサンプラーが記載されていることがありますので、まずは推奨に合わせたサンプラーを指定するのがよいでしょう。モデル推奨のサンプラーでないと意図した画像がでてこない可能性があります。
以下、現在主流の定番サンプラーです。
- DPM++ 系
-
特に「DPM++ 2M」がよく利用されます。仕上がりのバランスに優れたサンプラーで、生成速度もそれなりに速く、安定した出力になります。適度に線がシャープになりますのでパキッとした画像がでやすいです。実写系、アニメ系どちらでも効果がありますが、どちらかというと実写系で人気が高いです。(最近のモデルだとアニメ系でもDPM++系推奨のものが多い)
- Euler 系
-
特に「Euler」「Euler a」がよく利用されます。因みに「オイラー(エー)」と読みます。比較的単純な計算ルートをとるので生成速度が速く、それでいて出力も安定しているため人気があります。DPM系より少しふんわりしたイメージの画像がでやすいです。相性問題も少なめで実写系、アニメ系どちらでも効果がありますが、どちらかというとアニメ系で人気が高いです。

「DPM++ 2M」の方が色塗りが濃く、「Euler」の方がさっぱりしていますね。好みの問題でもありますが、絵柄の違いはわかるかと思います。
細かいことをいうと収束性のあるなしで「Euler」「Euler a」や「DPM++」「DPM++ SDE」と名前が少し変わるのですが、難しい話になるので今回はスルーします。(もし調べる場合はSDE系、ODE系と検索してみください。)
簡単にいうと、実直に目的とする画像を目指すのが「Euler」や「DPM++ 2M」などで途中の変化がないことから高い再現性があります。逆に生成途中に適宜”ゆらぎ”を入れて寄り道をし、偶発的な変化を入れるのが「Euler a(Euler Ancestral)」「DPM++ SDE」(名前にaやSDEと付くもの)などで、再現性に乏しくなりますが生成途中で発生した間違いを訂正しやすくなるのが特徴です。
とはいえ最初のうちはあまり気にしなくても大丈夫です。収束性があろうがなかろうがどちらでもちゃんと綺麗な画像が出力されます。先にも書いた通り、まずはモデル推奨のサンプラーを選んでおけば大丈夫です。
例えば「WAI-illustrious-SDXL」というモデルであれば「Euler a」が推奨と書いてあります。
2. Schedule Type (スケジュール タイプ)
サンプリング中にノイズをどんな配分で減らしていくかを決める設定です。「スケジューラー」とも呼ばれます。
画像生成の最初はノイズだらけで始まり、徐々にノイズを取り除いて最終的にノイズがゼロ(0)になったら完了となるわけですが、このノイズ除去のペース配分を決めているのが「スケジューラー」です。
モデルによってノイズ除去中の動作は異なっていますが、例えば最初に構図を決めて、後半は細かいディテールの調整に割くようなノイズ除去配分をしているならば、
- 前半で大まかな構図を決めるためノイズを大きく減らす
- 後半は少しずつ除去させることで細部を丁寧に整える
といった感じでノイズ除去のタイミングと強度を決めるのがスケジューラーの役割です。名前の通り仕事のスケジュール調整を担っていると思っていただければ大体合っています。
モデルによってノイズ除去の仕方が異なること、またサンプラーとの相性もあるので、これも推奨値がモデル内に書かれているならばそれに従うのが無難です。よくわからなければスケジューラーには「Automatic」という自動で選択する便利なモードがあるので標準設定のまま進めても良いです。
スケジューラーに関しては、モデル詳細ページに特に記述がない場合がありますので、その際は「Automatic」で様子を見るのがよいでしょう。モデルやサンプラーから自動で最適と判断されるスケジューラーが指定されます。

スケジューラーによる絵柄の変化は少ないことが多い(たまに大きく違うこともありますが)ので、最初からいきなり詰める設定でもありません。「Automatic」で進めて、画像生成に慣れてきたらどのように変化するかを試験すればよいでしょう。
※正直、サンプラーとスケジューラーの組み合わせ最適化は沼なので、慣れてくるまでは推奨値安定です。
一応、現在主要なスケジューラーは以下の通りです。
- Automatic(オートマティック)
-
モデルやサンプラーに応じて、適したスケジューラーを自動で選ぶモード。迷ったらこれで大丈夫です。
- Simple(シンプル)
-
基本形のスケジューラーで、モデルの学習時に近い配分でノイズ除去を行ないます。どこかに大きく配分を偏らせることはないので無難な選択にはなります。各種スケジューラーの比較用として使いやすい。名前の通りシンプルですがこれが良い結果になるモデルもありますので試す価値はあります。Animaモデルではむしろこっちが推奨かも?
- Karras(カラス)
-
ノイズ除去の中盤~後半を丁寧に行なうスケジューラー。適合するモデルで使用すると細部の描写力などがあがったりするので、このスケジューラーを好んで使う方も多いです。モデルやサンプラーによってはAutomaticで選ばれることもあります。
- Exponential(エクスポネンシャル)
-
名前の通り指数関数的に配分する方式で、はじめはゆっくり、後半で急激にノイズを減らします。初期段階で構図が安定しやすく変化が素直。シャープな印象になりやすいです。DPM++ 2M系サンプラーと相性がよいようです。
- Uniform(ユニフォーム)
-
ノイズ除去の速度が一定なスケジューラーです。癖が少なく、モデル本来の傾向を見やすいですが、低ステップ数には不向き。
- SGM Uniform (SGM ユニフォーム)
-
Uniformの亜種で、SGM(スコアベース生成モデル)に基づいた均等配分でスケジュール調整を行います。SDXL系モデルや軽量モデルでの相性がよいようなので、Illustriousモデルなどを利用する場合はKarrasと一緒に検討してみる価値はあります。
因みに、サンプラーとスケジューラーを合わせて「DPM++2M Karras」と併記したりすることもあります。この場合は双方の指定があることになっていますので、それぞれに設定してあげましょう。
3. Sampling Steps(サンプリング ステップ)
ノイズから画像を完成させるまでに何回調整を行うかを表す数値です。単に「ステップ数」とも呼ばれます。
例えば、ステップ数を「20steps」と指定すると、20回に分けてノイズを減らしながら画像を作っていきます。
上記スケジューラーは、このステップ内で完成画像に向かうようスケジュールを組みます。
一般的に、ステップ数が多くなればなるほど調整回数が多くなることから「細部が整いやすく」「形が安定」して品質が向上していきます。それに比例して生成時間が長くなります。

ただ、増やせば増やすだけ良いかというとそうでもありません。
各ステップでは、「今の画像を少しだけ理想に近づける」計算が行われていますが、十分に整ってきた後は、追加のステップで改善できる余地が少なくなります。つまり、いずれ頭打ちになり効果が薄くなります。また、収束しないサンプラーでは、ステップ数が多くなると構図が変わる場合があるため、無闇に増やすのが正解でもありません。
あまり改善もしない、生成時間だけが延びる、むしろ後半に変なノイズ除去してしまうことでのっぺりしてしまう場合もあるので、ほどよい設定にするのが理想です。
これも推奨値はモデル詳細のページに書かれていることが多いです。「WAI-illustrious-SDXL」ならば推奨ステップは「15~30」となっています。
一般的には、以下のような感覚で設定されるとよいかと思います。
- 20〜30 Steps:よく推奨値として指示されることが多く一般的な数値
- 10〜20 Steps:高速を謳ったモデルや、試し打ちのために設定することが多い
- 30 Steps以上:細部を少し詰めたい時に検討
4. Width / Height
生成する画像の横幅(Width)と縦幅(Height)です。いわゆる「画像サイズ」「画像解像度」と呼ばれるものです。
今までの用語は少し分かりづらいものが続いていましたが、こちらはシンプルに出力画像サイズの指定をする項目です。今回は標準設定のまま生成しましたので「1024×1024ピクセル」の設定になっているかと思います。
ただ、実際はもう少し細かい意味があります。画像サイズは、
- 構図の作りやすさ
- 細部の入り方
- 破綻のしやすさ
- VRAM使用量
- 生成時間
などにも大きく影響します。
VRAM使用量や生成時間は分かりやすいかと思います。画像が大きければそれだけ処理は重くなります。
Stable Diffusionのモデルは、その学習時に使われた解像度や、そこから想定される解像度の傾向があります。そのため、極端に大きい・小さい画像サイズや不自然な縦横比にすると、モデルの想定から外れるため構図が崩れたり、人物の手足や背景が不安定になったりすることがあります。
特に横長でキャラクターの全身を入れようとすると顔部分などで破綻しやすくなったり、一人指定(1girl,1boy)でも複数人生成されたりと思った画像が出力されなくなる可能性があります。(顔破綻などについては拡張機能で改善可能)
モデルの詳細ページに「解像度の推奨」の記載があるのはこれが理由で、そのモデルに合った解像度設定にすることが推奨されています。例えば、「WAI-illustrious-SDXL」モデルであれば「1024×1024ピクセル以上」が推奨されています。
もし、さらに繊細な高解像度画像が欲しい場合は、後述する「Hires.fix」による高解像度化を使うのが推奨されます。画像生成においては、この「推奨解像度で設定・生成してから後で高解像度化する」という手順が一般的です。高解像度化もAIによる補間を行ないますので、一般的な拡大と違ってジャギなどは発生しづらく、しっかり繊細になります。
5. CFG Scale (CFGスケール)
プロンプトにどれくらい強く従わせるかを決める設定です。
正式名称は「Classifier-Free Guidance Scale」なので、ガイダンススケールなどとも呼ばれます。
プロンプトによる指示があったとき、そのプロンプト内容をどれだけ忠実に従わせるかを数値で指定します。
値を低くするとプロンプト内容の忠実度が下がりますが、自由度が高くランダム性や創造性が高くなり、モデルがより自由な解釈で出力するようになるので、思っていた以上に構図や雰囲気がよい方向へ向かう事があります。
値を高くするとプロンプト内容をより忠実に守ろうとするため、細部まで忠実に表現しようとします。ただし、値を大きくしすぎると過度に追従してしまい、指示部分が強調されすぎて色や構図が破綻してしまうことがあります。

技術的には「プロンプトを見た場合、この方向に画像を整えたい」という予測と、「プロンプトを見ない場合なら、こう整える」というふたつの予測の差分を利用して、どれだけプロンプト側へ生成を寄せるか決めています。CFGスケールを上げるとモデルは「この画像はもっとプロンプト通りであるべき」と強く判断し、結果指定した要素が徐々に強調されるようになります。「プロンプト方向への補正量」を決めているのがCFGスケールです。
これは各ステップごと、生成過程の全行程で実施されるので影響が強いパラメーターです。過剰に設定すると飽和して焼き付きが起きたり、構図が不安定になったりしますので、適度な値にすることが大切です。
SFGスケールもモデルの詳細ページで推奨値が公開されている場合があります。例えば、「WAI-illustrious-SDXL」モデルであれば「CFGスケール:5-7」と推奨値が記載されています。
他のモデルでも大体は「4~7」辺りで推奨されていますので、まずはこの値で様子を見るのがよいでしょう。
6. Batch count / Batch size (バッチ カウント / サイズ)
生成を何連続で何枚同時に行うかを指定します。
- Batch count
-
何回に分けて生成するかを決めます。2以上を設定すると、その回数分だけ生成を実行します。
- Batch size
-
1回の生成で何枚同時に生成するかを決めます。2以上を設定すると、その枚数分だけ同時生成します。
例えば「Batch count = 4」「Batch size = 1」と設定すると「1枚ずつ4回生成」します。
逆に「Batch count = 1」「Batch size = 4」と設定すると「1回の生成時に4枚同時生成」します。
Batch sizeを増やすとVRAM消費が増えて負荷が高くなりますが、パソコンの性能に余裕がある場合は一回ずつ生成するより効率的に複数枚生成できる場合があります。1回1枚が限界である場合は、Batch countの方を増やして生成枚数を増やします。
特に同じ設定で何枚も出力できるので「複数候補を出す」ための機能として活用できます。
7. Seed(シード)
画像生成の出発点となるランダム値です。「シード値」と呼んだりします。
Stable Diffusionでは、最初にランダムなノイズから始まりますが、そのノイズをどのような状態で作るかを決めているのがシードです。「最初のノイズの作り方を決める番号」になります。
同じプロンプト、同じ設定でもシードが変わると出発点が変わるので違う画像がでてきます。勘違いしやすいですが、別に最初のノイズの中に何か絵柄の要素があるわけではなく、最初のノイズを再現するための鍵を記録するのがシードで、あくまで「同じ条件をそろえたときに、同じ出発点を再現するための番号」です。
初期値は「-1」となっており、毎回ランダムな値がシードとして設定されることを意味しています。最初は何枚も画像を生成して良さそうな出力になるものを探しますので、「-1」と設定してランダム値で模索します。
もし「これだ!」と思った画像が出力された場合、その画像のシード値を控えておきます。そのシード値を入力して同じプロンプト、同じ設定にすると、今度は全く同じ画像が出力されるようになります。
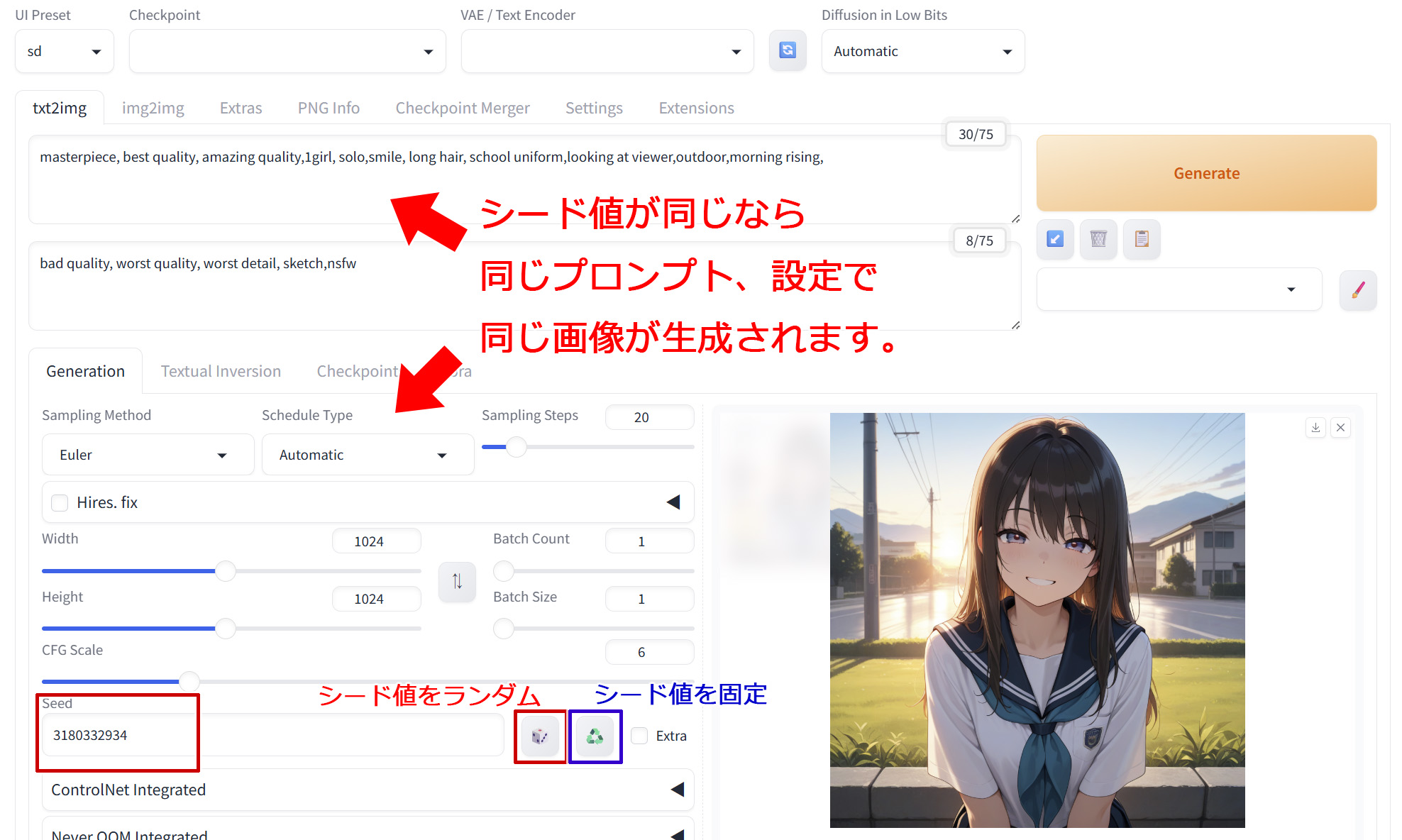
Seedの右にあるサイコロマークを選択すると「-1」が入ってランダム化、右のリサイクルマークのようなアイコンを選択すると今の画像のシード値が挿入されます。このシード値を控えることで、あとから同じ画像を再現させることができます。
シード値を固定したまま、少しプロンプトを変更したり、CFGスケールを変えたりすることで、元画像に近い状態で画像の変化を見ることができるようになります。構図やポーズの大枠がある程度似たまま、細部だけを調整しやすくするためにシードは便利に使えます。
8. Hires. fix (ハイレゾ フィックス)
高解像度化の設定を行います。いわゆる「アップスケール」です。
チェックを入れることで高解像度化が有効になります。
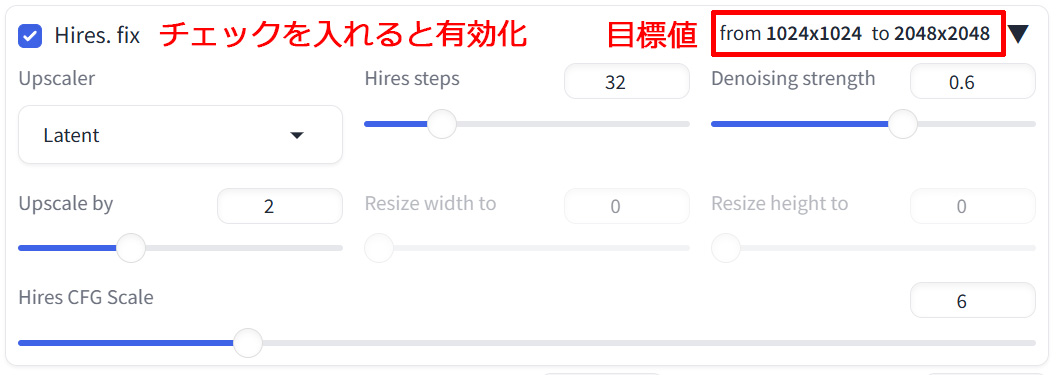
最初から高解像度になるよう「Width / Height」を設定する方法もあるのですが、モデルによってはこれをやると構図が崩れる可能性があり、最初の生成は低めの解像度で実施したいことが往々にしてあります。
ですが、やはり高解像度の繊細な画像にしたい!という場合に活躍するのが「Hires. fix」です。
一般的にイメージされる「画像の拡大」は、すでにある画像を拡大してピクセルを補間するという方法になりますが、Hires. fixは拡大の際にもう一度生成処理をかけて絵を描き直すため、単純な拡大よりもノイズが少なく繊細な画像が作られます。内部処理的にはimg2img(画像から画像を生成)に近く、実際img2imgを通して高解像度化と再調整を行う処理のようです。
画像生成AIにおけるアップスケールの基本的な考え方になり、モデルのサンプル画像もHires. fixでアップスケールを行ったと書いていることが多いです。
ただ、単純な拡大と違って「再生成」をしているので、設定によっては「顔の表情が少し変わる」「構図が少し動く」などの変化が見られる場合があります。また、計算量が多いためGPUやメモリにも高負荷がかかります。

Upscaler(アップスケーラー)
どの方式(アルゴリズム)で拡大するかを設定します。
主流のアップスケーラーは主に以下のふたつです。
- Latent 系 (レイタント)
-
Latentは、Stable Diffusionが内部で扱っている潜在表現(latent)を先に拡大する方式です。Stable Diffusion は、まず圧縮された表現であるlatent空間上で処理し、最後にVAEで画像へ戻しますが、このlatentの状態から拡大を始めます。最初の画像からAIによる出力であることを利用した生成AIらしい高解像度化です。
ただ、latentから始めるので最初から拡大すること前提であればいいのですが、最初は拡大せず出力画像を確認してからシード値を固定し、同じ設定で再度拡大させようとするとまれに構図が大きく変わってしまうことがあります。また、設定によってはやや柔らかく見えることもあります。
- ESRGAN 系(イーエスアールガン)
-
Stable Diffusion専用の仕組みではなく、単一画像超解像のための独立したアップスケーラーです。恐らく一般的にイメージされる画像拡大の方法で、出力された画像を直接見て細部を補いながら拡大するアップスケーラーです。ピクセルを対象に「その周囲にあることが予想される細部」や「高周波の質感」を補って拡大します。Latentがlatent空間で行うのに対し、ESRGANは画像空間で処理する点が異なります。
出力される画像を元に拡大処理を始めるので、全く変化しないわけではありませんがLatentより構図が安定しやすく、そのまま髪の毛、布地、背景の細かな模様などで「描き込みが増えた」ように見えやすくなります。ただ、過剰にシャープになることがあり、イラスト系では質感が変化することがあります。
実はアップスケーラーは標準以外のものをインターネット上からダウンロードして追加することができます。
有名どころとしては「4x-AnimeSharp」や「RealESRGAN_x4Plus Anime 6B」「4x_fatal_Anime_500000_G」「4x-UltraSharp(4x-UltraSharpV2)」などがあり、それぞれ得意分野が異なります。標準のアップスケーラーより好ましい結果になる場合もあるため、別途導入してもよいでしょう。
アップスケーラーの保存場所は、StabilityMatrixを利用している場合「\Data\Models\ESRGAN\」です。
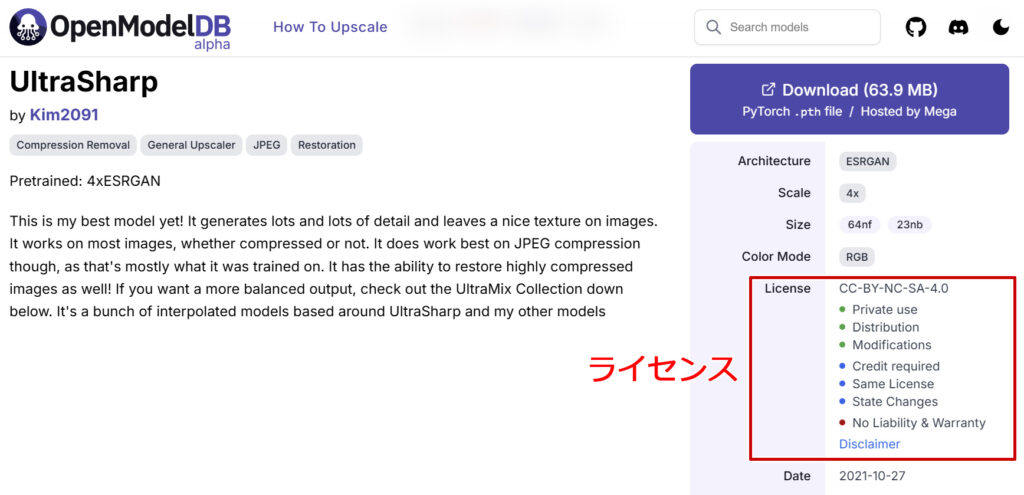
ただ、アップスケーラーも学習モデルのひとつなのでライセンスがあります。有名どころは大体「CC-BY-NC-SA-4.0」ライセンスで、「クレジット表記」「非商用」「作品の改変があった場合も同じCCライセンスを継承」などが求められています。非商用のことが多いので注意してください。(※「RealESRGAN_x4Plus Anime 6B」はBSD-3-Clauseライセンスのようです。)
アップスケーラーを通して生成した画像もライセンスが引き継がれるのか、というのはまだ生成AIに関する法整備が曖昧な現時点では中々厳密な答えがないような状況なので、各人のモラルに任せる部分もあるかと思いますが、モデルやLoRAだけでなくアップスケーラーにもライセンスがあることは認識しておいてください。
Hires steps
高解像度化で書き直すステップ数を決めます。
通常のSampling Steps(サンプリングステップ)が1回目の生成(本生成)のステップ数だとすると、こちらは高解像度側の再生成のステップ数です。それぞれ独立したステップ数で設定できます。
「0」にすると本生成のステップ数と同じ回数だけ高解像度化処理が行われます。ただ、本生成時である程度は繊細になっておりノイズが少ない状態なので、本生成時のステップ数より少なくても大丈夫です。ステップが多くても結果はあまり変わらず生成時間だけ増えるので、本生成の半分程度でよいかと思います。
Denoising strength(デノイジング ストレングス)
高解像度化においてどれくらいの強度でノイズ除去をするか決めます。ノイズ除去強度とも呼ばれます。
Hires. fixにおける拡大は単なる拡大ではなく生成AIによる再生成を行っていますので、同じくノイズ除去を行いながら画像を整えていきます。最初に少しノイズを加えてから再び拡散過程で描き直し高解像度化していますが、この「ノイズ除去強度」は「どの時点まで画像をノイズ側へ戻すか」を決める値です。
値が低いほど開始地点が完成画像に近く、高いほどランダムノイズ寄りの地点から再生成します。
「Denoising strength = 0」に近いほど追加するノイズが少ないので元画像を強く参照したまま「軽い手直し」をします。なるべく元画像から崩したくない場合に値を低くします。
「Denoising strength = 1」に近いほどノイズを多く加えて元画像からかなり崩して「ほぼ作り直し」に近づきます。構図が少し崩れる可能性がありますが、より品質が上がる可能性があります。
ただ、値が低すぎると細部を作り直す余地が足りず、ぼやけたり、眠たい絵になったりして劣化することがあります。逆に高すぎると自由度が高くなりすぎて構図が大きく変わってしまうことがあります。
アップスケーラーや元画像によって適切な値は異なりますので、ノイズ除去強度の値を少しずつ変えて実験しながら適切な値を確認していくとよいでしょう。大体は0.4~0.6くらいでかけることが多いです。
Upscale by
どのくらい大きくするかを決めます。ここでは元のアスペクト比を維持しながら縦と横を倍率指定します。
「Upscale by」で値を「2」にすると、例えば「1024×1024」が縦横「2倍」になり「2048×2048」になります。
実用的なのは「1.5倍~2倍」で、これ以上大きくしようとすると負荷が高くなりすぎてプログラムが落ちる可能性があります。生成時間もかなり長くなる可能性がありますので、大きくしても2倍までが実用的です。私のパソコン環境では2倍にするとたまに落ちます。(4Kサイズでも3840×2160ですからこれ以上大きくする必要性はあまりないでしょう。)
隣に「Resize width to」「Resize height to」がありますが、これは横幅と縦幅を任意に指定できる箇所です。ただ、Hires. fixは単純な拡大やトリミングではないので、元画像のアスペクト比から大きく外れるとうまく高画質化できない可能性があります。アスペクト比は維持する方が無難(後から画像編集ソフトで編集した方がよい)なので、正直あまり使わない設定です。
Hires CFG Scale
Hires. fixによる高解像度化に適用されるCFGスケールです。
通常のCFGスケールが本生成におけるプロンプトの忠実度を決める値でしたが、こちらはHires. fixに適用されるCFGスケールで、「高解像度化中にどれだけプロンプトに従わせるか」を別個に決める値になります。
Hires. fixでは元画像を土台にしつつノイズを少し加えて再びノイズ除去をしていくのですが、そのときプロンプト条件にどれだけ強く引っ張られるかを決めます。
値を上げるほどプロンプトへの忠実度が強くなります。このため、細部の構図や情景をより忠実に反映してさらにディテールを強化することができますが、高くしすぎると通常のCFGスケールと同じく過剰に要素が強調され焼けた感じになったり、粒状感、硬い陰影、不自然な輪郭が出やすくなったりします。
逆に低くすると元画像を保ちながら比較的おだやかに高解像度化しやすくなります。ただ、低くしすぎると細部への書き込みも少なくなるので単に拡大しただけのような画像になる場合もあります。
最初の元画像の時点で大まかな構図は決まっているので、そこまで細部を強調させる必要がないことも多く、このため通常のCFGスケールと同じにするより、Hires側のスケールは少し低めにする運用もよく見られます。ほとんど手を加えない「Hires CFG Scale : 1」という生成例もありますので、これも色々試してみるとよいでしょう。
生成画像のプロンプトや設定を後から確認する
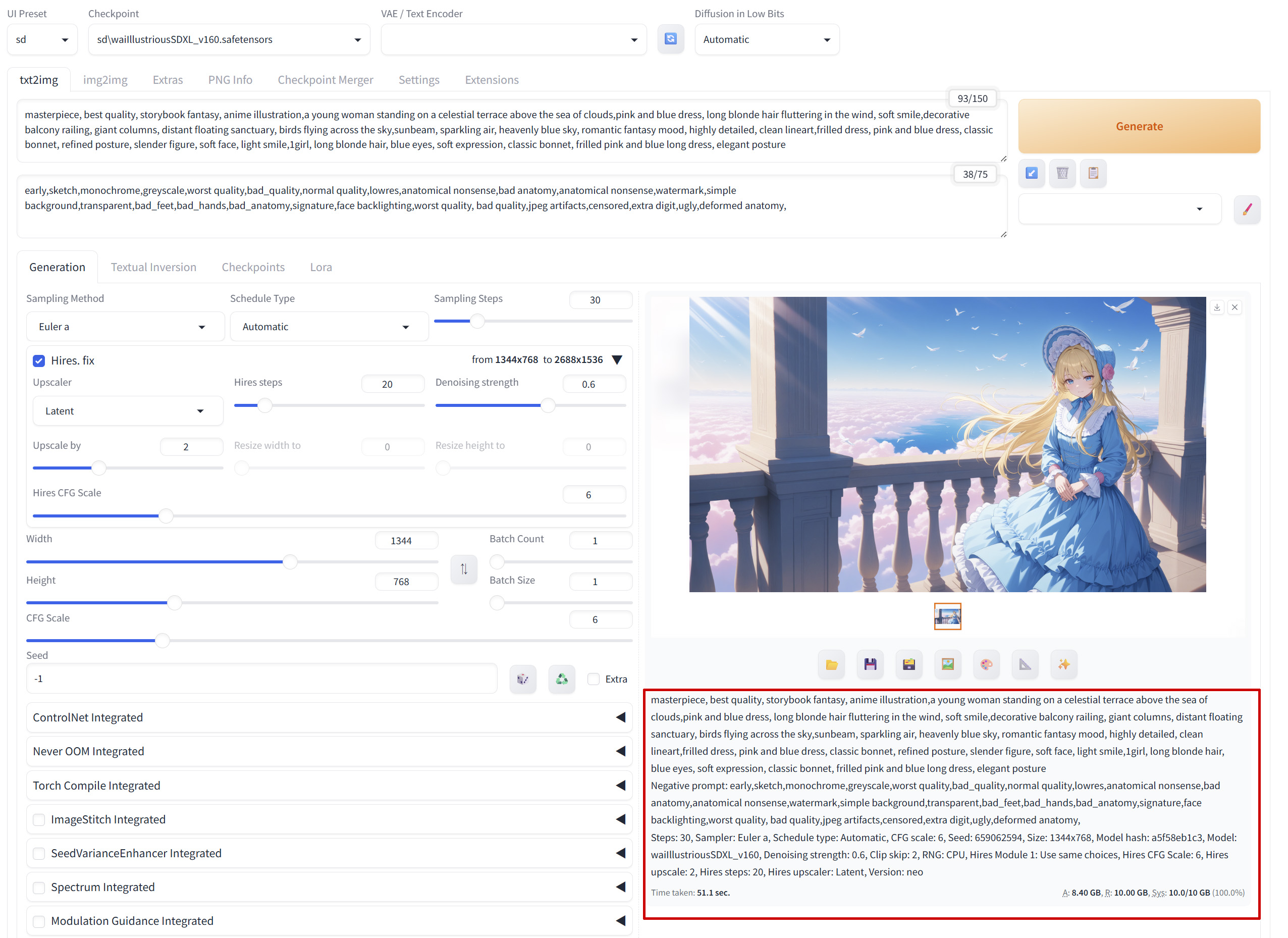
生成した直後であれば、「txt2imag」の「Generation」タグで生成画像のすぐ下に、この画像を生成したときのプロンプトや各種設定などが表示されています。
例えば、生成した画像をみて
- どんなプロンプトだったか
- どのモデル、サンプラー、スケジューラーを使ったか
- Sampling Steps や CFG Scale はいくつだったか
- Seed は何だったか
などを確認することができます。
では、すでに生成している過去の画像を確認する方法はあるか、というとちゃんとあります。
生成済みの画像の詳細を確認する「PNG info」
WebUI画面の上部メニューに「PNG info」というタグがありますのでここを選択します。
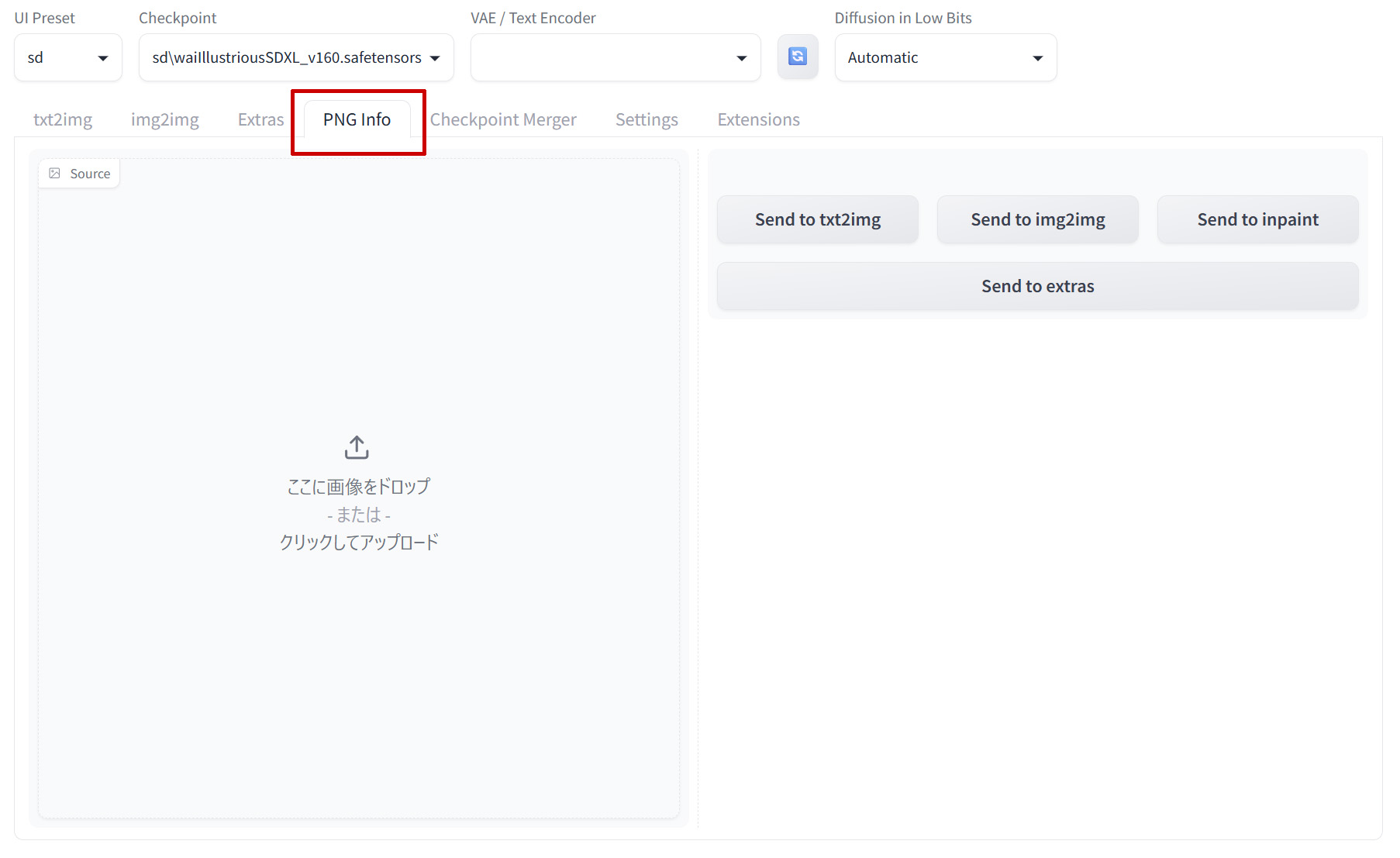
右の画面に調べたい画像をドラッグ&ドロップ、またはクリックして該当の画像をアップロードしてください。
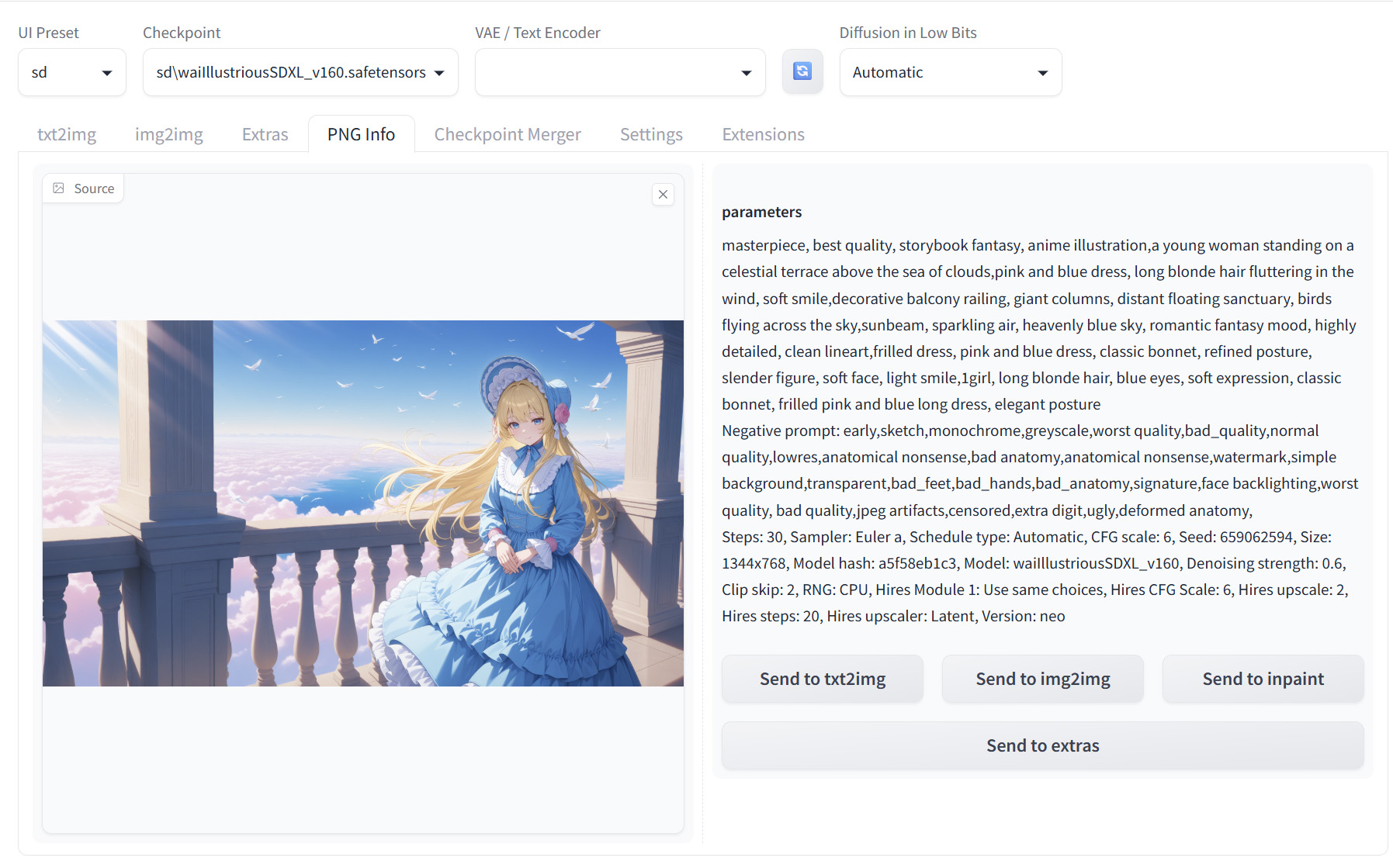
これで該当の画像を生成した際のプロンプトや各種設定を確認できます。
Stable Diffusion WebUIの標準出力は「.png」なので「PNG info」という名前ですが、設定を変えればJPG画像でも出力できますし、このPNG infoで読み込ませればJPG画像でも確認できます。
これは、画像ファイルのEXIF情報の中にデータが入っているためです。PNG画像では「Parameters」というメタデータ内、JPG画像では「ユーザーコメント」というメタデータ内に入っています。
後からPhotoshopなどの画像編集ソフトで編集した画像だとこれらメタデータが削除されてしまう場合がありますので、あくまで生成時の画像を参照するのが基本です。
各種機能(img2imgなど)に情報を送る
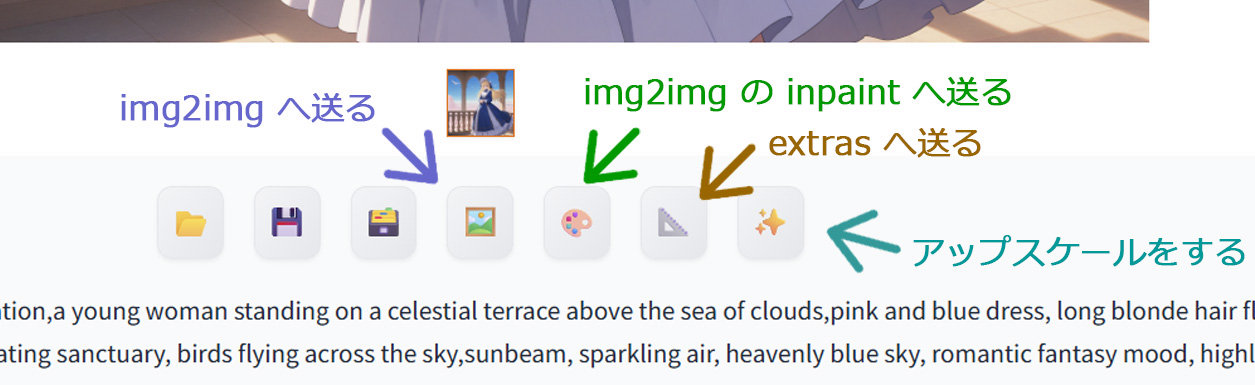
PNG Info では、画像に埋め込まれた生成情報を読み取るだけでなく、その内容を「txt2img」「img2img」「inpaint」「extras」などの各タブへ送り返すことができます。
「parameters」の下に4つのボタンがあり、それぞれに情報を送ります。
- Send to txt2img
-
読み取った生成情報を txt2img タブへ送る機能です。「テキストから画像」という意味です。
今までプロンプトテキストから画像を生成していましたが、この画面へプロンプトや各種設定情報を送ります。つまり、設定だけを引き継いでもう一度再生成するための送り先です。画像は参照しません。
「過去画像からもう一度同じ設定で再生成させたい」「プロンプトを少し変えたい、モデルやCFGスケールだけ変えて比較したい」などのときに利用します。
- Send to img2img
-
画像の内容と生成情報の両方を img2img タブへ送る機能です。
img2imgは名前の通り「画像から画像を生成」という意味で、プロンプトや設定情報のほか「生成画像そのもの」も一緒に送ります。txt2imgとの大きな違いは、こちらは元画像も入力として使う点です。
出力された画像は気に入っているが、もう少し詳細を詰めたいときに利用します。例えば「構図を保ったまま服装や髪型を変えてみたい」「元画像をベースに少し描き直したい」などのときに利用します。
- Send to inpaint
-
画像と設定を inpaint 用の編集画面へ送る機能です。画像とプロンプト情報を一緒に送ります。
inpaint(インペイント)は、画像全体を作り直すのではなく、マスクした部分だけを修正するための機能です。元画像をなるべく保ちながら、一部だけ直したいときに向いています。
例えば「表情集を作りたい(顔だけ再生成)」「手だけ直したい」「背景の一部を修正したい」など、マスクを使ってより細かな部分のみを修正、再生成させたい時に利用します。
- Send to extras
-
画像を Extras タブへ送り、主にアップスケールや後処理に使う機能です。
生成タブではなく、すでにできている画像に対してアップスケールや画像補正系の後処理を行う場所です。アップスケーラーも標準では生成が入らない「Lanczos」「Nearest」「ESRGAN」のみ入っています。
単純な拡大をしますので構図等が崩れる心配はありませんが、ならばPhotoshopなどで画像を引き伸ばした方がよい結果になるような気もします。
画像生成後にすぐ各種タブへ送る
画像生成後、すぐに生成画像をimg2imgなどへ送ることもできます。
Generationタブで画像を生成後、生成画像のすぐ下にあるボタン類で「img2img」や「img2img inpaint」へそのまま画像を送ることができます。生成時にアップスケールを忘れていた場合でも後から実行できます。
まとめ と Q&A集
最後までお読みいただきありがとうございました。お疲れ様でした。
前回の記事と合わせて、これで「StabilityMatrix」→「Stable Diffusion WebUI」の導入から、実際に画像生成を行い、各種設定まで一通りお話できたかと思います。これでもまだ基本部分なのですから、Stable Diffusionはすごいできることが多いですね。(img2imgとかinpaintとかControlNetとか拡張機能とかまだまだあります。)
できればこれらも徐々に記事にできればと思ってはいるのですが、現在は多忙な状況のため、正直なところこの2つの記事を書いて力尽きています。
なので、これからの記事を書くかどうかは仕事の忙しさによるのであまり期待しないで他のウェブサイトを参考にしていただければと思います。
一応、調べるに当たってヒントになるような言葉をQ&A集として載せておきますので参考までに。
- 顔がどうしても崩れてしまう
-
特にキャラクターの全身画像を生成しようとすると、顔描写にまでステップが割けないので顔が崩れやすいです。Hires. fixで高解像度化するときに多少改善はされますが、拡張機能を使うのがおすすめです。
「ADetailer」と呼ばれる有名な拡張機能があり、これをインストールすると顔だけ、手だけなどで再生成させることができ、劇的に描写が改善します。Stable Diffusionを使うならほぼ必須の拡張機能です。Forge Neoバージョンでも使えます。「CivitAI」ではどの部位を検出するかという検出場所のバリエーションを増やすADetailer用追加データも公開されています。
- プロンプトでどのような単語を使えばいいか分からない
-
インターネット上で有志の方が「こういったポーズ、動作をさせたいならこのプロンプト」というリストを沢山公開してくてれているのでこれらを参考にしましょう。ChatGPTなどに聞いてみるのもおすすめ。
- 二人以上のキャラクターを書きたい
-
プロンプトで指示もできますが中々反映してくれませんので拡張機能を使うのがおすすめ。Forge Neoバージョンなら「Forge Couple」、互換性の高いreForgeなら他に「Regional Prompter」などの拡張機能も使えます。
- 日本語化できる?
-
「stable-diffusion-webui-localization-ja_JP」という拡張機能で一応できますがすべての項目で日本語化はできず(特に拡張機能は英語のままが多い)、一部だけ日本語になる程度です。必要なら入れてみてください。日本語、英語併記もできます。
- 画像の一部だけ修正したい
-
img2imgやinpaint、ControlNetなどで可能です。img2imgやinpaintが使いやすいので、最初はこれらを利用してみるとよいでしょう。Illustrious系モデルが優秀なので最近ControlNetは少し下火気味。
- 「Illustrious」や「NoobAI」って何?
-
そのモデルがどの系統を土台にしているかという表記。そのモデルがどの学習系統・作風・プロンプト文化の流れ(歴史)にあるものなのかを示しています。モデルの歴史みたいなもので、記事執筆時点ではIllustrious系(イラストリアス)やNoobAI系(ヌーブAI)が人気。「CivitAI」でも新しく公開されるモデルはIllustrious系がほとんど。
最初のころは「SD1.5」などが人気で画像生成AIの世界を牽引していました。現在となっては顔や手足の描写間違いが多いモデルなので、今始めるならこれらが改善されたIllustrious系が無難です。
本当はもっと新しいFluxとかQwenとかZ-Imageとかでてきてはいるのですが、既存のモデルやLoRAとの互換があまりなく、またライセンスの問題があったりと中々主流にならない状態。これからに期待です。
- LoRAって何?
-
追加学習データ「LoRA(ローラ)」のことです。大元のモデルである「Checkpoint(チェックポイント)」内では学習されていないような特殊なポーズ、キャラクター、服装などを追加学習したものです。チェックポイントと一緒に読み込ませるとこれら特殊効果を追加で反映させることができます。「CivitAI」にいっぱい公開されています。LoRAにもIllustrious系などベースモデルがありますが、必ずしも合わせる必要はないです。ただ、最適化はされていないのでなるべくは合わせます。
一部LoRAにはトリガーワード(Trigger Words)と呼ばれる、LoRAの学習内容を読み込ませる特殊なプロンプトが必要になることがあります。LoRAの詳細ページに書いてありますので確認してください。キャラクター再現系のLoRAは大体トリガーワードがあります。
- 動画をやってみたい
-
Stable Diffusion WebUIでもできなくはないのですが、少し管轄外。動画をやってみたい場合は、「ComfyUI」や「Wan2GP」の方が向いていますので、こちらを使ってみましょう。
