


パソコンをある程度長く操作してきた方は一度経験したこともあるでしょう。
コンピューターにはお馴染みの怪現象「文字化け」。
例えば「文字化け」とちゃんと入力したにも関わらず、別の環境へそのデータを持って行ったら「譁?ュ怜喧縺」と意味不明な文字になってしまったなど。一度は経験したことあるかと思います。私はMacOSからWindows環境へデータを移動させるときによく見ます。
一見「データが壊れてしまったのか?」と不安になってしまいます。しかし、元の環境に戻すと問題ない・・・
これは、別にデータが壊れてしまったわけではなく、パソコンが文字データを扱うための構造に起因する問題です。つまり、ちゃんと理論的に説明できる不具合なのです。
ということで、「文字化け」はなぜ発生してしまうのか、その原因をここで解説したいと思います。
パソコンはどうやって文字を扱っているのか - 文字コードについて
文字化けについて理解するためには、まず「パソコンはどうやって文字を扱っているのか」を理解する必要があります。
パソコンは「0」と「1」だけしか本来扱えない
パソコンが扱うことができるデータというのは、実は「0」と「1」だけなのです。(2進数)
電流が流れているのか、流れていないのか。電気の「ON」と「OFF」のみだけなのです。
これは不便に見えるようですが、もともと人間より圧倒的に計算速度が早いですし、エラー訂正がやりやすくなるため正確にデータを取り扱うことができるようになります。コンピューターではこちらのほうが都合がよいのです。
しかし、これでは「0」と「1」だけしか表現できません。他の文字はどうやって表現するのでしょうか。
文字コード
ここで登場するのが「文字コード」と呼ばれるものです。
パソコンは「0」と「1」を羅列させることはできます。例えば「110」と表現することは可能です(バイト表現といいます)。そこで、各文字や記号に対応するようなバイト表現リストのようなものを人々は作りました。これが「文字コード」です。
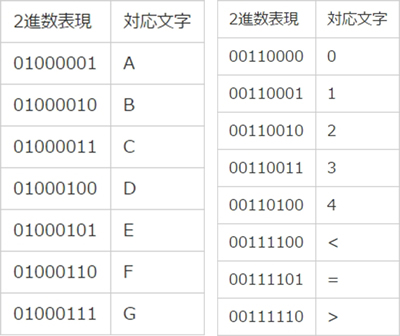
以上は「ASCIIコード表」というものの一部です。
このように、様々な文字が「1」と「0」のバイト表現で表せるようになっています。
この文字コードをパソコンは辞書のように利用することで、日常生活で必要な文字や記号が扱えるようになっています。2進数表記だと長くなりすぎるので、人間にも見やすくするためこれを変換して「16進数表記(0~9とA~Fの16文字で数える)」でリスト表記していることもあります。
そして、2進数表記をしたとき、8文字(=8bit=256通り)あれば主要なアルファベットと記号がすべて表せるようになるため、8bit=1Byte(バイト)というデータ容量の単位の起源となっています。
日本語など「漢字」を用いたりする言語の場合は、8bitでは全然足りないので16bit使うような文字コードが作られました。日本では「Shift_JIS」、さらに業界標準文字セット「Unicode」などが有名です。
使われている文字コードが16bitである場合、それを明示的に示すため「0x」という符号を頭に付けて表現したりします。「0x」の後に続く文字列は16進数ですよ、と示しています。「Shift_JIS」では「あ」を表すために16進数表記で「0x82a0」(1バイト目が82、2バイト目がa0という意味)が割り振られています。
IMEパッドで文字コードに触れてみる
Windowsが標準で搭載する文字入力補助ソフト「IMEパッド」で文字コードに触れることができます。
テキストファイルを作成、適当に文字(ひらがななどの全角文字が確実)を入力した後にエンターキーで確定させる前に「F5」キーを押してください。IMEパッドが開いたら左のメニューから「文字一覧」を選びます。言語バーからの起動方法や、そもそもIMEパッドとはなに?という方は以下の記事を参考にどうぞ。
◯ブログ内リンク:読み方が分からない漢字は「IMEパッド」で検索!
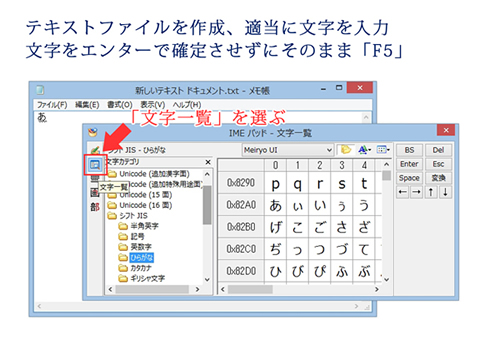
では、試しに「文字カテゴリ」で「シフト JIS」(下の方にあります)を探して展開→「ひらがな」を表示させてみます。右に「あ」などがでてくるのでそこにマウスを置いてみます。(マウスオーバーといいます)
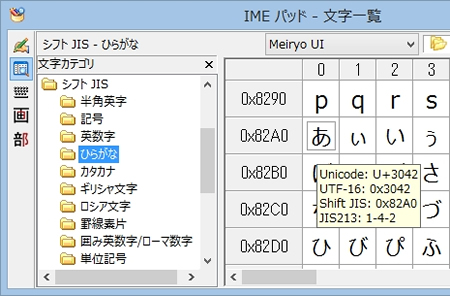
すると吹き出しのようなものがでてきます。ここで「あ」を表すための文字コードと対応文字列が確認できます。「あ」という文字はUnicodeなら「U+3042」、「Shift JIS」なら「0x82A0」が割り振られているということがわかりましたね。
1つの文字を表すためだけの話なのですが、文字コードによってその対応文字が異なることがよく分かったかと思います。
文字コードの互換性が「文字化け」を生む
さて、これでパソコンが文字を扱う原理がわかったと思います。
文字コードを使って「1」と「0」の羅列を文字に変換しているわけです。
世の中には様々な文字コードが存在します。コンピューターの歴史とともに人類が色々考えてきたからです。それぞれの文字コードにはメリットもデメリットもあり一長一短です。そのため、ソフトウェアが扱うことができる文字コードにも少しずつ違いがでてきます。特に「半角カタカナ」がやっかいです。
では、「Shift_JIS」を使った文書で半角カタカナ「アイ」と入力したとします。
「Shift_JIS」では「アイ」は「0xB1 0xB2」という文字列で表現できます。実際の文書にはこの文字列を記録して保存します。次回この文書を開くとき、「この文書は Shift_JIS を使って書かれた文字である」ということが認識できれば「Shift_JIS」の辞書を使って正しく内容を確認できます。
しかし、場合によっては「この文字は何で書かれているのだろう」と使用していた文字コードが分からないということが起きることもあります。その場合、取り敢えず知っている文字コードを当てはめて文書を読もうとします。
この時、本来は「Shift_JIS」で作った文書を「EUC-JP」という文字コードを使って読み込んでしまったとします。「EUC-JP」はMacOSなどで利用されています。すると、「Shift_JIS」で「アイ」に対応する文字列「0xB1 0xB2」は、「EUC-JP」だと「渦」(0xB1B2)という漢字が割り当てられてしまっているので「アイ」を「渦」であると誤解釈してしまいます。
「アイ」が「渦」となって表示されてしまいました。これが文字化けの原理です。
因みに、対象文字がない場合は「?」などが表示されたりします。

特に「UTF-8」というインターネット上で多く使われている文字コードと、日本で普及している「Shift_JIS」への変換の際に文字化けが発生しているケースが多くみられます。また、WindowsとMacOSとの間でデータをやりとりする際にも扱う文字コードの違いで文字化けが起きやすくなっています。
文字化けしてしまったら?
原理的には、正しい文字コードで読み込ませてあげれば読めるようになるはずです。
例えば、多くのWebブラウザでは文字コードのエンコード(変換)機能があり、それを使うことで使用する文字コードを変更させることができます。正しい文字コードを当てるためには「総当り」して一個ずつ試していくしかありません。
例えば、Internet Explorerならばページを開いたら右クリック→「エンコード」で文字コードを変更できます。正しく表示されている中で、この作業により別の文字コードへ変更すると壮大に文字化けするので一度試してみると面白いでしょう。
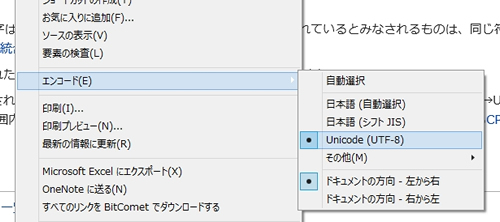
▲エンコード
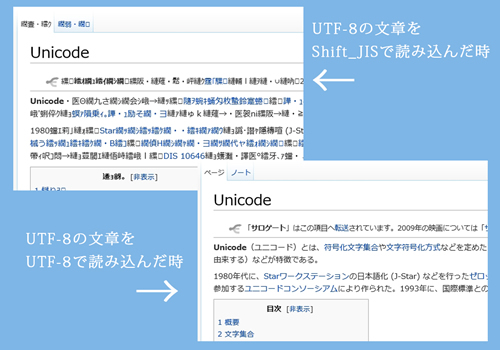
▲文字化けの実例
また、メールなどでももちろん文字化けが起こる可能性があります。その場合もエンコード機能を使ってある程度復元させることも可能です。「Windows Live メール」などなら下記Microsoftサポートの公式サイトで紹介されています。
Windows Live メール や Outlook で受信したメールが文字化けしていて読めない!
https://support.microsoft.com/ja-jp/kb/909435/ja
また、以下の様なサイトでは様々な文字コードを使って確認することができるようになっています。
元の文字コードと一致すればある程度復元可能です。ただ、文字化けしてしまった時にいくつか文字情報がなくなってしまうこともあるので、完全な復元はあまり期待できません。
文字化け解読ツール「もじばけらった」
http://lab.kiki-verb.com/mojibakeratta/
まとめ
以上、今回は文字化けの原理と修復方法について、その原理から解説してみました。
文字コードは、別の言い方をすればそのソフトウェアが読むことができる「言語」です。そこへ、別の読むことができない言語(文字コード)がやってきても知っている言葉ではないので読めません。私が英語が全然読めないのと同じです(それは違う?)
で、読めないなりに自分の知っている言語で解読を試みようとするわけですが、もちろん失敗するので文字化けが起きてしまうのです。
文字化けというのは、いつも意味不明な「ランダム」な化け方をするのではなく、ちゃんとした理由があって化けています。構造的な不具合なので仕組みがわかれば対処法も自ずとわかってきます。もし、今後文字化けに出会ってしまったら、文字コードを変更してみたりすると解決するかもしれません。