

簡単にネットショップを開設できる「STORES(ストアーズ)」ですが、2023年3月時点では商品データをCSVでダウンロードする機能がありません。
もし、「STORES」から別のショップサービスなどへ移転したいとき、商品情報を一括で再登録するために全商品データが欲しくなるのですが、公式では一括ダウンロード機能が無いため、別の手段を取る必要があります。
この記事では、スクレイピングツールを利用して「STORES」の商品データを自動で収集、CSVやExcelファイル(.xlsx)で出力する方法をご紹介します。
スクレイピングツール「Octoparse」を利用してデータを抽出
「STORES」では公式機能として商品データをダウンロードする機能が無いため、別のツールを利用します。
利用するツールは「Octoparse(オクトパース)」と呼ばれるWebスクレイピングツールです。無料プランと有料プランがありますが、今回は無料プランの機能で十分対応できます。

スクレイピング【scraping】とは、プログラムによってWebサイト上にある情報を自動で収集する技術のことです。
つまり、今回実施することは「STORES」に登録してある商品データ(タイトル、価格、詳細など)をスクレイピングツール「Octoparse」によって自動収集し、CSVやExcelファイルにしてまとめる方法となります。数百の商品データがあっても自動で収集できますので、「STORES」からの移行を考えている場合には便利に利用できます。
「Octoparse」を利用するためには、一度無料会員となる必要があります。
まずは以下の公式サイトから会員登録をします。
因みに、料金表は下記から確認できます。今回利用する無料(フリー)プランは、上限として「一回実行あたり最大1万レコード」となっていますが、十分なレコード数です。もし、上限メッセージが出たらタスクを再度構築すればまた利用できます。
ログインできたらツールをダウンロードします。
「Octoparse」はデスクトップアプリとして使います。「Windows版」と「Mac版」の2つがありますので、使用しているOSに合わせてダウンロードしてください。
インストールに注意点はなく、インストール先を指定するのみです。
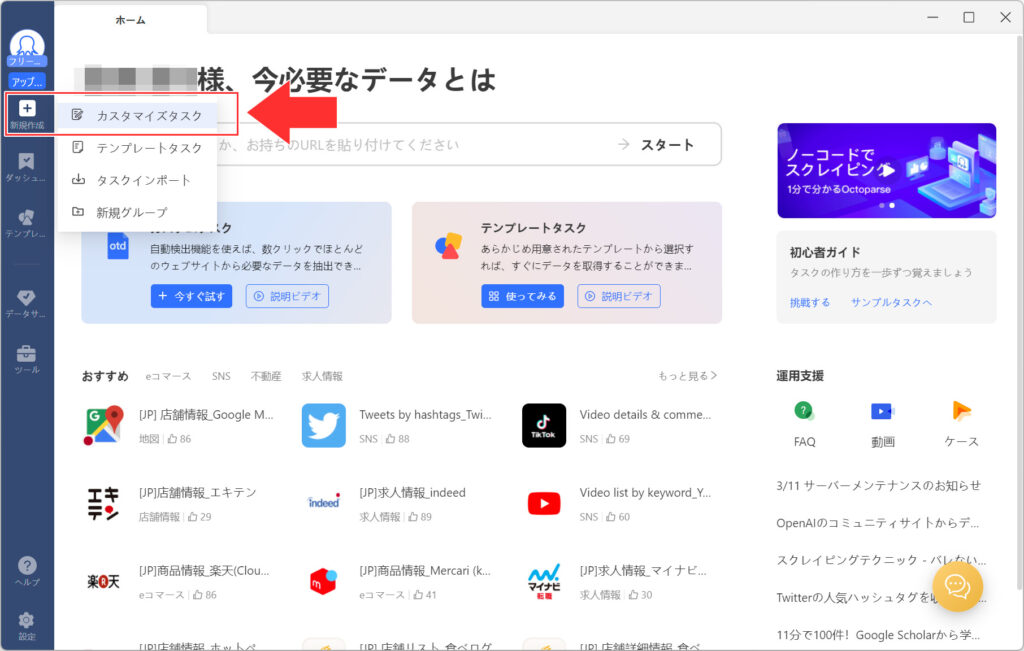
アプリが起動したら、左上の「新規作成」を選択、さらに「カスタマイズタスク」を選択してください。
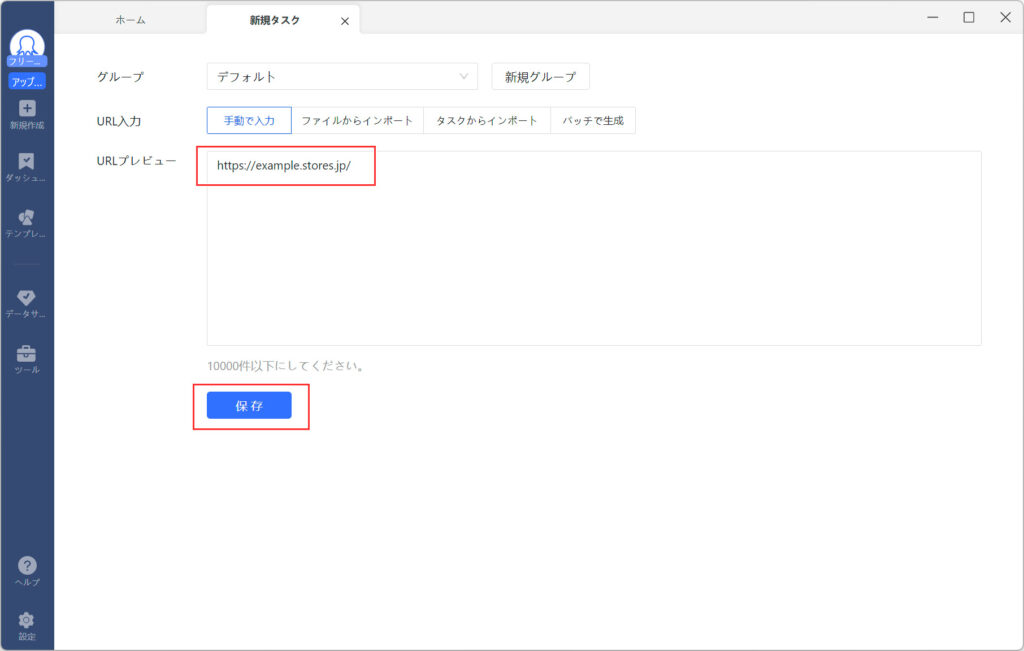
「URLプレビュー」に運営中のSTORESのURLを入力します。商品個別のページではなくトップページのURLで大丈夫です。入力したら「保存」を選択します。
今回は一回きりの利用を考えているのでグループ名はデフォルトにしていますが、わかりやすい名前を付けて管理することもできます。
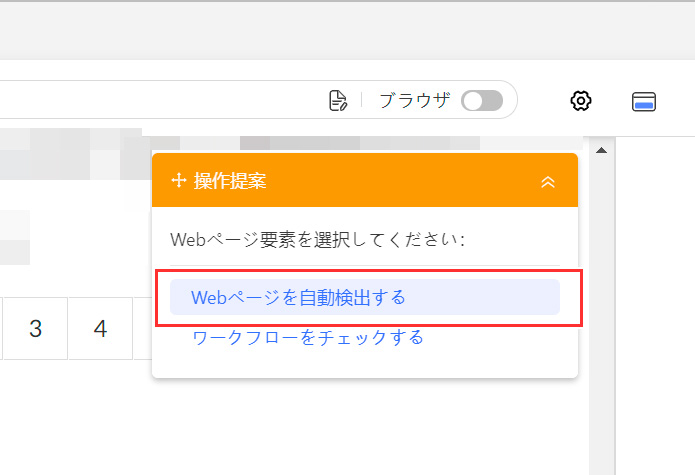
ページが表示されたら、右上のウィンドウにある「Webページを自動検出する」を選択してページを解析してくさい。
解析が終了したら「ページネーションを設定する」の「編集」を選択してください。
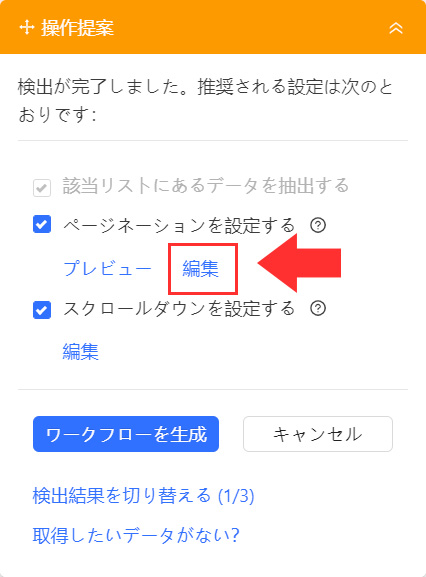
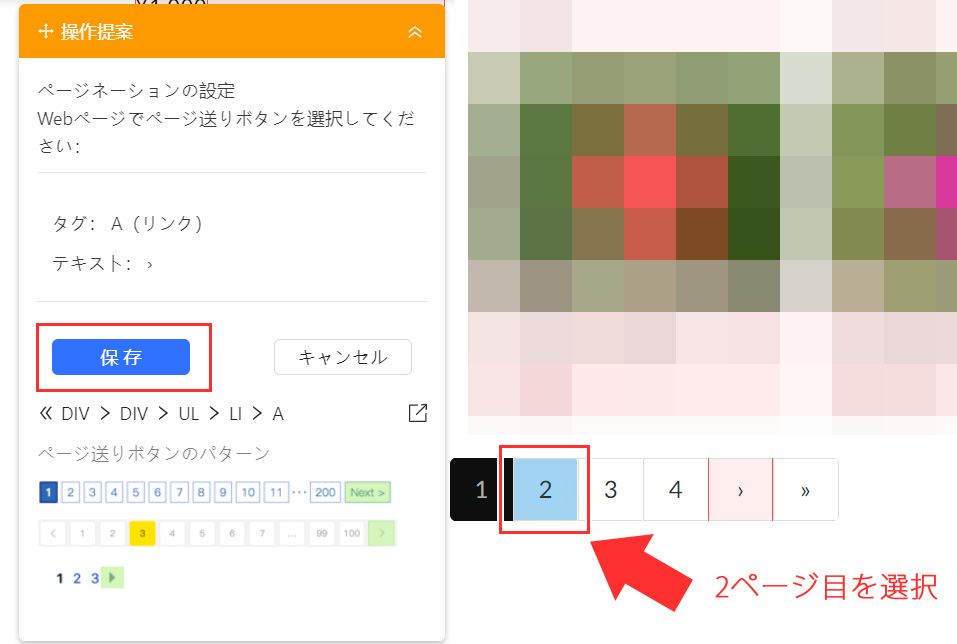
商品数が多いと複数ページに渡って商品が登録されています。この場合であっても自動で2ページ以降の商品データを解析できるよう、「次のページのボタン」を指定してあげます。
1ページ目から解析が開始されますので、次のページである「2」のボタンをクリックして選択します。指定できたら「保存」を選択してください。
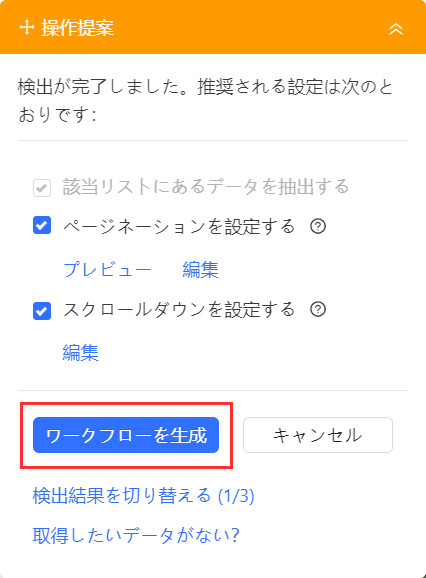
画面が戻ったら「ワークフローを生成」ボタンを選択します。
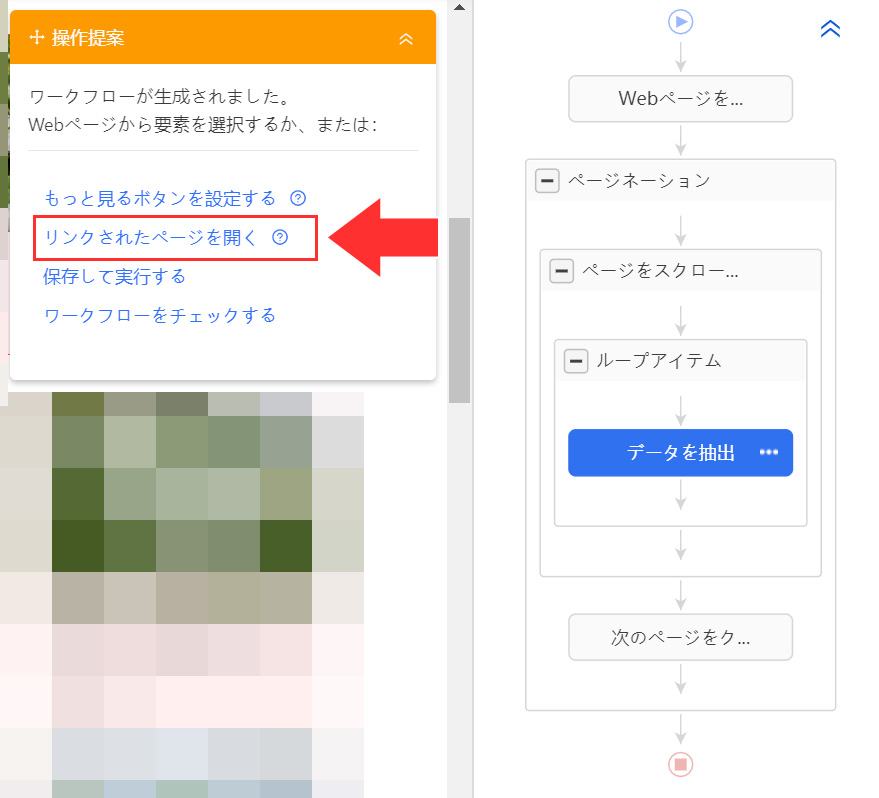
ワークフローが生成されますので、すぐさま操作提案にある「リンクされたページを開く」を選択してください。
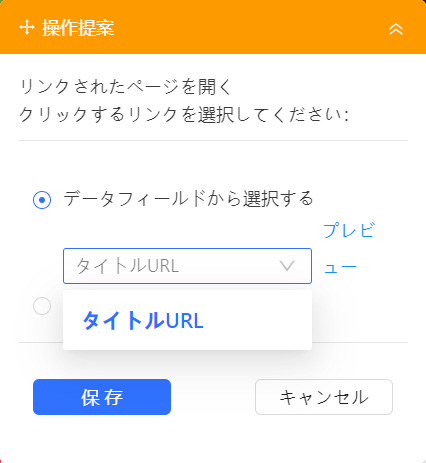
「データフィールドから選択する」にチェックを入れ、プルダウンメニューから各商品ページへアクセスするためのリンクを指定します。ここでは「タイトルURL」となっています。指定できたら「保存」を選択してください。
商品ページが開き「ワークフロー」に「URLをクリック」が追加されます。ここで操作提案から「Webページを自動検出する」を選択してください。
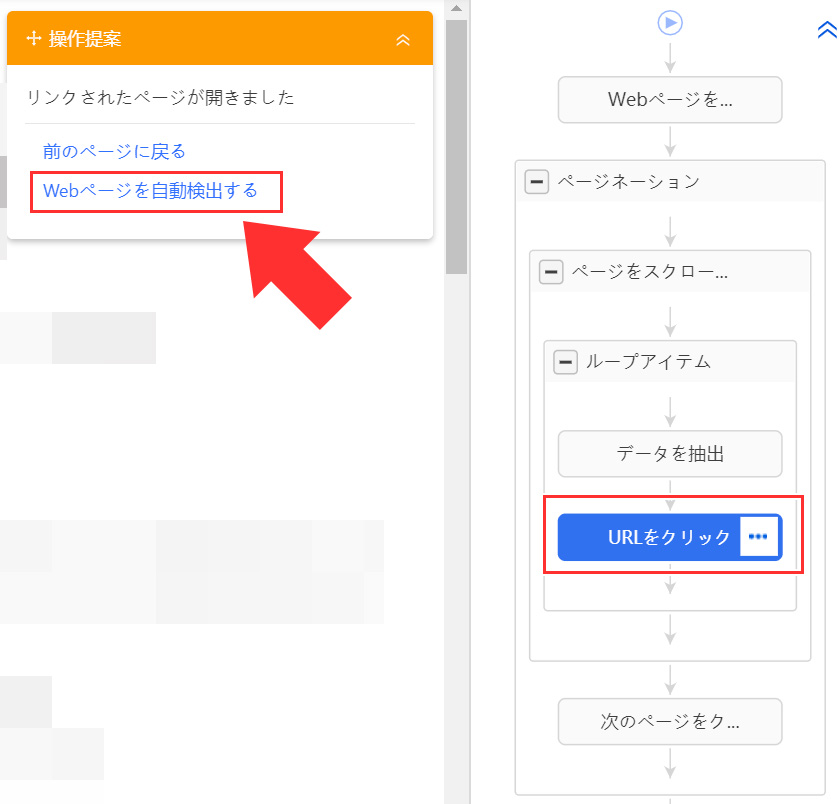
ページの解析が始まりますが、ここで解析を中断するため「自動検出をオフ」を選択してくさい。
最後まで解析してもよいのですが、余計な項目まで選択されることがあり、欲しい情報だけを指定して抽出できるようにするため一度中断させます。
ただ、完了させても後から項目の削除は可能ですので、無理に中断しなくても大丈夫です。
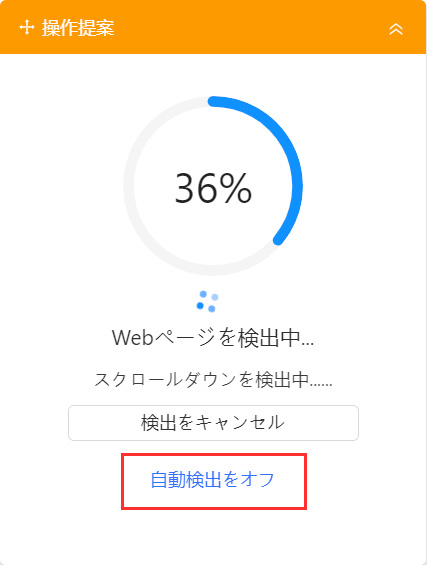
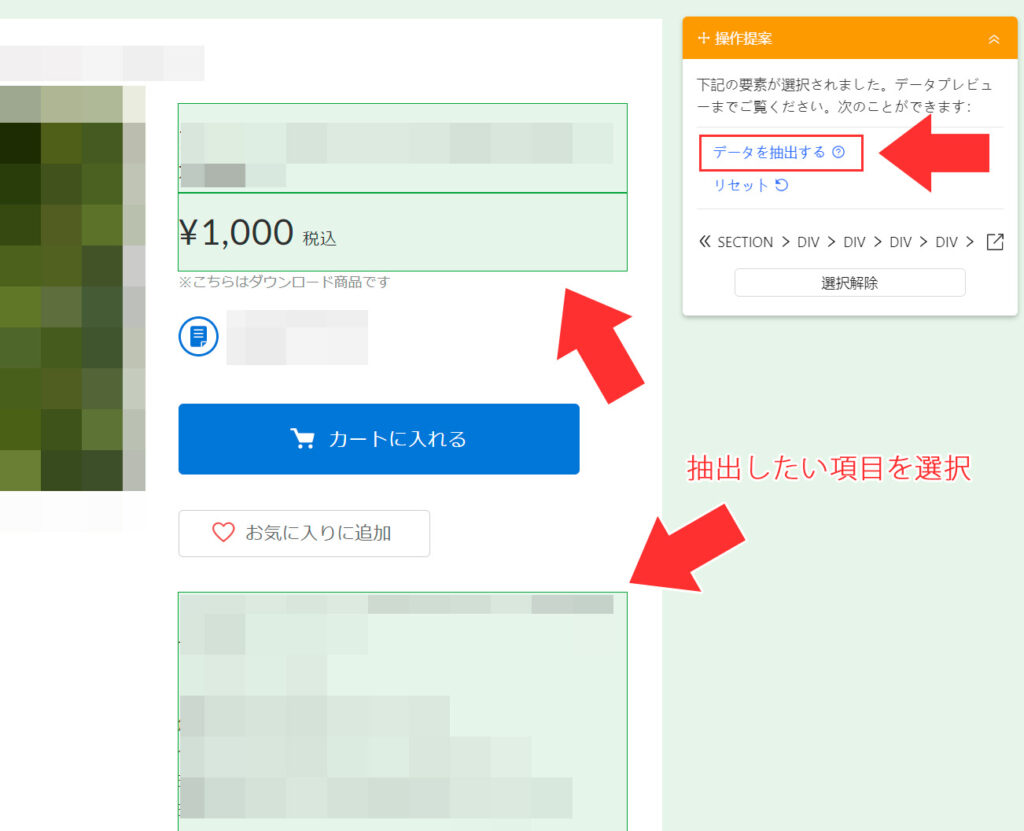
解析が中断しますので、今度は抽出したい項目を手動でクリック・選択してください。
選択された項目は緑色の枠に囲まれます。この選択された項目が抽出項目となります。選択し終わったら「データを抽出する」を選択してください。
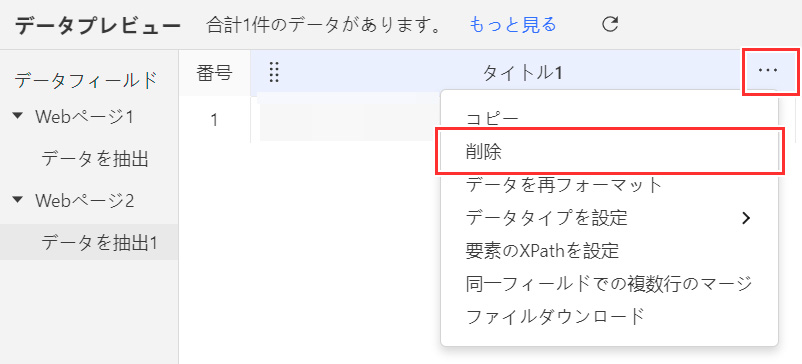
抽出項目から削除したい場合は、画面下にある抽出項目にある「タイトル」や「フィールド」と書かれたバーをマウスオーバーすると表示されるごみ箱マーク、または三点マーク「…」で表示されるメニューから削除できます。

スクレイピングという行為は、非常に多くのアクセスを伴うことから相手側のサーバーに大きな負荷をかける場合があります。
「Octoparse」は標準設定でもそれなりの速度でページを読み込みますので、サーバー側の処理能力や転送速度に余裕がある場合は抽出の時間も短くできるのですが、アクセスが多い時間帯などでサーバー側の処理が間に合わなくなる場合、またアクセスが早すぎてページが表示される前に抽出が始まってしまう場合などでは正しくデータを抽出できないことがあります。
具体的には「抽出されたデータがNULL値である」や「ステータスコード429」というエラーを出して抽出できない場合があります。
また、スクレイピングされる側としては過剰なアクセスとして迷惑していることも多々ありますので、ユーザー側としては急激なアクセスとならないよう調整するのがマナーと言えるでしょう。
そこで、アクセスタイミングを調整してみたいと思います。
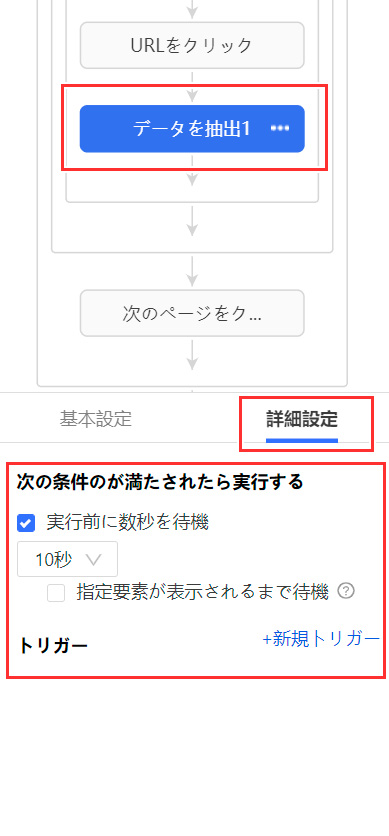
ワークフローの「データを抽出」を選択した状態で、下にある「詳細設定」を開きます。
「実行前に数秒を待機」にチェックを入れて待機時間を指定してください。ここで指定した時間は一時待機してデータの抽出を待つようになります。全体の抽出時間は長くなってしまうのですが、サーバー側の処理もゆるやかになり、また時間をかけることでWebページがしっかり表示されてから抽出を開始できるためにエラーの発生が少なくなります。
余裕を持って7秒~10秒くらいの待機時間があるとほぼエラーが無くなります。
調整が終わったら、右上の「実行」ボタンを選択してください。
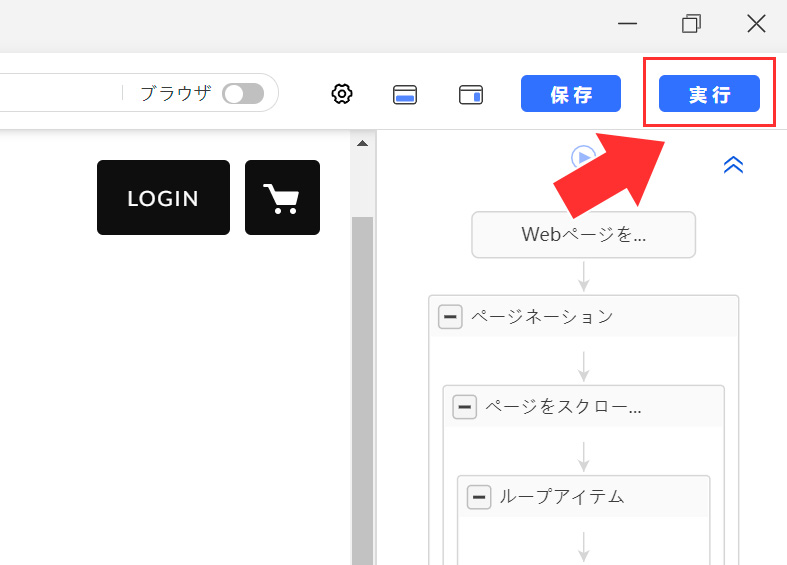
「タスク実行」画面が表示されたら、「ローカル抽出」の「通常モード」を選択してください。

タスクが実行されてデータの抽出が開始されます。
終了するまでそのまま待ちます。中断する場合は「一時停止」「停止」ボタンで可能です。
ここで抽出中にエラーが発生する場合は(実行ログで確認)、アクセスが早すぎる可能性があります。先ほど設定した「実行前に数秒を待機」の時間指定をより長くしてみてください。
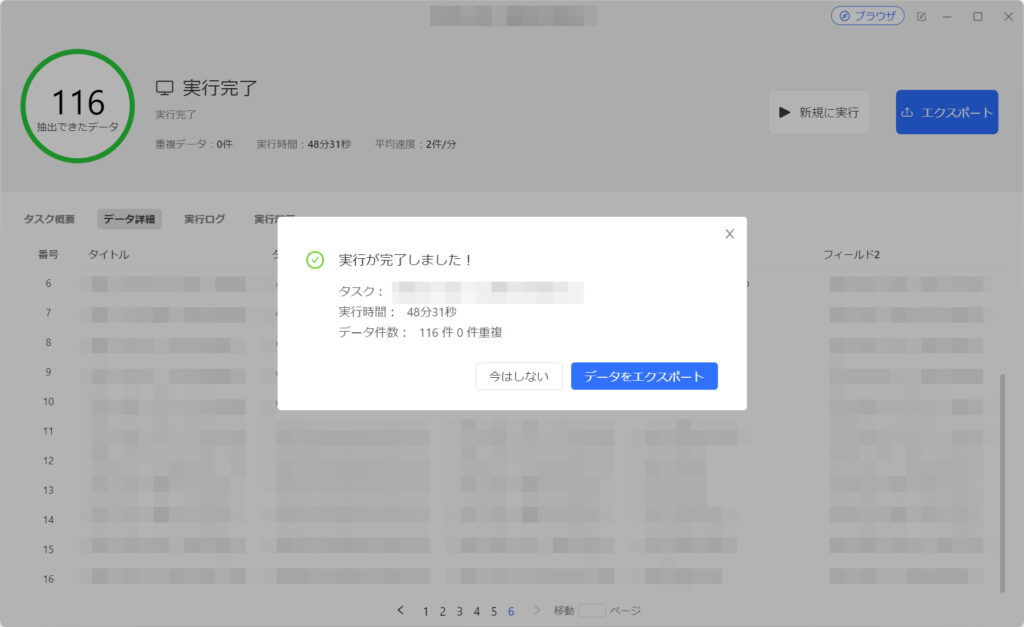
「実行が完了しました!」となれば抽出終了です。
「データをエクスポート」ボタンを選択して結果をダウンロードします。因みに、今回は「待機時間10秒」で「116件」のデータを抽出し「48分」の時間がかかりました。
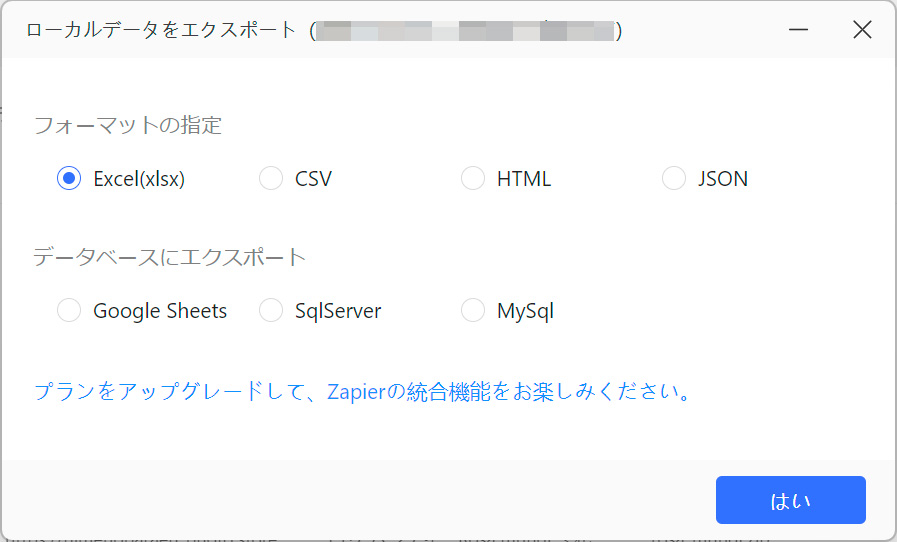
エクスポート画面では各種フォーマットに変換してデータをダウンロードできます。
用途に応じて選んでいただければと思いますが、Webサイトの移転の場合は「Excel」または「CSV」ファイルを選んでおくのが無難です。文字化けの危険がある場合は特に「CSV」が理想です。
ファイルがダウンロードされれば作業完了です。
保存された場所は「保存先」に記載されています。保存された場所の「フォルダーを開く」ボタンもありますので見失うことはないでしょう。
ダウンロードされたデータを移行先のインポートツールのフォーマットに合わせて調整すればOKです。

まとめ
少し長くなりましたが、公式で商品データをダウンロードできない「STORES」から、スクレイピングツールを利用して各ページの商品データを抽出・ダウンロードする方法を解説いたしました。
「Octoparse」はページ送りがあっても自動で移動してすべてのページを参照してくれますので、タスクの設定さえしてしまえば後はすべて自動実行してくれるのが優秀です。
本当は公式でダウンロード機能を実装してくれるのが一番なのですが、ヘルプページを見ても「現時点では実装していない」となっていますので、しばらくはこの方法が有効かと思います。
同業他社である「BASE」にはこの機能あるので(CSVで一括編集も可能)、「STORES」も早く対応してほしいですね。